GreenBuildings 1: Exploratory Analysis & Outlier Removal¶
5. Removing Outliers With Isolation Forests
6. Recomendations & Next Steps
Introduction ¶
I started this project a while back with a goal of taking the 2016 NYC Benchmarking Law building energy usage data and do something interesting with it. I originally attmpted to clean and analyze this data set to try to find ways to reduce builings' energy usage and subsequently their green house gas emissions. After a few iterations I thought it might be interesting to see if I could predict the emission of green house gases from buildings by looking at their age, energy and water consumption as well as other energy consumption metrics. This is somewhat of a difficult task as the data was very messy and in this first blogpost I will cover how to perform,
- Exploratory data analysis
- Identify and remove outliers
Since I will completing this project over multiple days and using Google Cloud, I will go over the basics of using BigQuery for storing the datasets so I won't have to start all over again each time I work on it. At the end of this blogpost I will summarize the findings, and give some specific recommendations to reduce mulitfamily and office building energy usage. The source code for this project can be found here.
Data¶
The NYC Benchmarking Law requires owners of large buildings to annually measure their energy and water consumption in a process called benchmarking. The law standardizes this process by requiring building owners to enter their annual energy and water use in the U.S. Environmental Protection Agency's (EPA) online tool, ENERGY STAR Portfolio Manager® and use the tool to submit data to the City. This data gives building owners information about a building's energy and water consumption compared to similar buildings, and tracks progress year over year to help in energy efficiency planning.
Benchmarking data is also disclosed publicly and can be found here. I analyzed the 2016 data and my summary of the findings and recommendations for reducing energy consumption in New York City buildings are discussed in the conclusions post.
The data comes from the year 2016 and is quite messy and a lot of cleaning is necessary to do analysis on it. The cleaning process was made more difficult because the data was stored as strings with multiple non-numeric values which made converting the data to its proper type a more involved process. One thing to keep in mind through out this post is that this is self-reported data, meaning our data is mostly biased, containinig outliers. Therefore, I will go over a few techniques for removing outliers in post.
Exploratory Data Analysis ¶
Since the cleaning was more tedious I created external functions do handle this processes. In addition, I also created functions to handle transforming and plotting the data. I kept these functions in seperate files Cleaning_Functions.py and Plotting_Functions.py respecively so as to not clutter the post. We import these functions along with other basic libraries (Pandas, Matplotlib and Seaborn) as well as read in the data file below:
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set()
from utilities.CleaningFunctions import (
initial_clean,
convert_GeoPandas_to_Bokeh_format,
group_property_types
)
from utilities.PlottingFunctions import (
plot_years_built,
make_interactive_choropleth_map
)
Here is we specifify a few datatypes as integers while reading in the Excel using the read_excel function from Pandas
df_2016 = pd.read_excel("../data/nyc_benchmarking_disclosure_data_reported_in_2016.xlsx",
converters={'Street Number':int,
'Zip Code':int,
'Year Build':int,
'ENERGY STAR Score':int})
There are about 13,233 buildings with different types of energy usage, emissions and other information. I'll drop a bunch of these features and only keep the following,
- Reported NYC Building Identification Numbers : [BINs]
- NYC Borough, Block and Lot : [BBL]
- Street Number : [Street_Number]
- Street Name : [Street_Name]
- Zip Code : [Zip_Code]
- Borough : [Borough]
- Year Built : [Year_Built]
- DOF Benchmarking Status :[Benchmarking_Status]
- Site EUI (kBtu/ft$^{2}$) : [Site_Eui]
- Natural Gas Use [N(kBtu) : [Nat_Gas]
- Electricity Use (kBtu): [Elec_Use]
- Total GHG Emissions (Metric Tons CO2e) : [GHG]
- ENERGY STAR Score : [Energy_Star]
- Water Use (All Water Sources) (kgal) : [Water_Use]
The terms in the square brackets are the column names used in the dataframe. In addition, we must do some basic feature engineering. The reported data gives us the metrics (NAT_Gas, Elec_Use, GHG, Water_Use) in terms of total volume. Using these metrics in comparing buildings of different sizes is not a fair comparison. In order to compare them fairly we must standardize these metrics by dividing by the square footage of the buildings giving us each metrics' intensity. We therefore have the following features,
- Nautral Gas Use Intensity (kBtu/ft$^{2}$) : [NGI]
- Electricty Use Intensity (kBtu/ft$^{2}$) : [EI]
- Water Use Intensity (kga/ft$^2$) : [WI]
- Total GHG Emissions Intensity (Metric Tons CO2e / ft$^2$) : [GHGI]
- Occupancy Per Square Foot (People / ft$^2$) : [OPSQFT]
- Age (years)
I wrote a basic function called initial_clean(). to clean the data create the additional features. We call it on our dataset and then get some basic statistics about the data:
df_2016_2 = initial_clean(df_2016)
temp_cols_to_drop = ['BBL','Street_Number','Zip_Code','Occupancy']
df_2016_2.drop(temp_cols_to_drop, axis=1)\
.describe()
The above table is only a summary of the numrical data in the dataframe. Just looking at the count column we can immediately see that there are a lot of missing valus in this data. This tells me that this data will be rather messy with many columns having NaNs or missing values.
It also looks like there is a lot of variation within this dataset. Just looking at the Site_EUI statistic, the 75th percentile is is 103 (kBtu/ft²), but the max is 801,504.7 (kBtu/ft²). This probably due to the number of different types of buildings in the city, as well as the fact that contains outliers.
The next thing I would like to see is how many of the buildings in NYC are passing the Benchmarking Submission Status:
plt.figure(figsize=(10,4))
df_2016_2['Benchmarking_Status'].value_counts()\
.plot(kind='bar',
fontsize=12,
rot=0)
plt.title('DOF Benchmarking Submission Status',fontsize=14)
plt.ylabel('count',fontsize=12)

Most buildings are in compliance with the Department of Finance Benchmarking standards. Let's take a look at the violators:
Violators = df_2016_2.query("Benchmarking_Status == 'In Violation' ")
Violators.head()
There's not much we can learn from this, if we can look to see if certain zip codes have more buildings in violation. First thing we do is group by the zip codes and count them to get the number of violations per zip code:
zips_df = Violators.groupby('Zip_Code')['Zip_Code'].size()\
.reset_index(name='counts')
Now we want to visualize the the number of violators per zip code. To make things interesting we will create an interactive choropleth map using the Bokeh Library. Bokeh is a great vizualization tool that I have used in the past. We get the shapes for New York City zip codes as a geojson file from this site. The geojson file can be read into a dataframe using GeoPandas.
import geopandas as gpd
gdf = gpd.read_file("../data/nyc-zip-code-tabulation-areas-polygons.geojson")
# GeoPandas doesn't allow users to convert the datatype while reading it in so we do it here
gdf["postalCode"] = gdf["postalCode"].astype(int)
We can see the basic contents of the GeoPandas dataframe:
gdf.head(2)
I noticed only a few of the zipcodes had actual names, so I wrote a script (GetNeighborhoodNames.py) to scrape this website to obtain each neighborhood's name. I pickled the results so we could use them here:
zip_names = pd.read_pickle("../data/neighborhoods.pkl")
We can attach them to our GeoPandas dataframe by joining them (on zip code),
gdf = gdf.drop(['PO_NAME'],axis=1)\
.merge(zip_names, on="postalCode",how="left")\
.fillna("")
Next, we'll left join our count of violators-per-zipcode zips_df to above dataframe and fill in the zip codes that do not have violations with zeros:
gdf= gdf.merge(zips_df, how="left", left_on="postalCode", right_on="Zip_Code")\
.drop(["OBJECTID","Zip_Code"], axis=1)\
.fillna(0)
gdf.head(2)
Now before we can use Bokeh to visualize our data we must first convert the GeoPandas dataframe to a format that Bokeh can work with. Since I already covered this in a previous blog post I won't go over the details, but here I used a slightly modified version of the function from that post:
bokeh_source = convert_GeoPandas_to_Bokeh_format(gdf)
Next we set bokeh io module to be in the notebook and use the function I wrote make_interactive_choropleth_map to create the in-notebook zipcode choropleth map:
from bokeh.io import output_notebook, show
output_notebook()
# We get the min and max of the number of violations to give the cloropleth a scale.
max_num_violations = zips_df['counts'].max()
min_num_violations = zips_df['counts'].min()
fig = make_interactive_choropleth_map(bokeh_source,
count_var = "Number Of Violations",
min_ct = min_num_violations,
max_ct = max_num_violations)
show(fig)
You can hover your mouse over the each of the zipcode and the map will display the neighborhood name and number of violations. From this we can see that Chelsea, Downtown Brooklyn and Long Island City neighborhood have the highes number of violations.
The fact that different neighborhoods have different numbers of violating buildings gives us the suspicion that the neighborhood may be correlated with the buildings energy usage, this could be because of building owners that are in voliation owning multiple buildings on a single lot or neighrborhood.
Now let's move back to analyzing the buidlings that are not in violation. First let's see the distributution of all buildings that are in different ranges of the Energy Star ratings:
bins = [0,10,20,30,40,50,60,70,80,90,100]
df_2016_2['Energy_Star'].value_counts(bins=bins)\
.sort_index()\
.plot(kind = 'bar',
rot = 35,
figsize = (10,4),
title = 'Frequency of ENERGY STAR Ratings')
plt.ylabel('Frequency')
plt.xlabel('ENERGY STAR Score')

We can see that the majority are within the 50-100 range, but a almost 1000 buildings have scores inbetween 0 and 10. Let's take a look at the distribution of building types. We will just take the top 10 most common building types for now..
df_2016_2['Property_Type'].value_counts()\
.head(10)\
.plot(kind = 'bar',
figsize = (10,4.5),
fontsize = 12,
rot = 60)
plt.title('Frequency of building type', fontsize=13)
plt.xlabel('Building Type', fontsize=13)
plt.ylabel('Frequency', fontsize=13)

The most common buildings in NYC are multifamily housing, then offices, other, hotels and somewhat suprisingly non-refrigerated warehouse space. I would have thought that there would be more schools and retail spaces than warehouses or dormitorites in New York City, but I don't know what the Primary BBL listing is.
Let's look at the Energy Star ratings of buildings across different building types, but first how many different building types are there? We can find this out,
print("Number of building types are: {}".format(len(df_2016_2['Property_Type'].unique())))
This is too many building types to visualize the Energy Star Score (Energy_Star) of each, we'll just look at just 5 building types, lumping the 54 into the categories into either:
- Residential
- Office
- Retail
- Storage
- Other
I built a function to group the buildings into the 5 types above called clean_property_type(...) and we use it below to transform the Pandas Series:
Property_Type = df_2016_2.copy()
Property_Type['Property_Type'] = Property_Type['Property_Type'].apply(group_property_types)
Now we can look at the Energy_Star (score) of each of the grouped buildings types:
bins2 = [0,20,35,50,65,80,100]
Energy_Star_Scores = Property_Type.groupby(['Property_Type'])['Energy_Star']
Energy_Star_Scores.value_counts(bins=bins2)\
.sort_index()\
.plot(kind='bar',
figsize=(13,6),
fontsize=13)
plt.title('Frequency of Energy Star Score by building type',fontsize=14)
plt.xlabel('Building Type and Energy Star', fontsize=13)
plt.ylabel('Frequency', fontsize=13)

Overall it looks like residential buildings have a lot more proportion of low Energy Star Scoring buildings when compared to office buildings. This is probably because there are much more older residential buildings than office spaces in New York City. We'll look at the distribution of the years in which builings of just properties of type: 'Multifamily Housing' and 'Office' were built:
plot_years_built(df_2016_2)

It seems like it's the opposite of what I thought, but the number of residential buildings is much higher and the majority were built right before and right after World War 2, as well as in the 2000s. The same is true about offices, however, without the uptick in the early 2000s.
Connecting To BigQuery ¶
Let's focus on the multifamily housing and office buildings to see what we can find out about them since these make up the majority of buildings and may offer the best return on investment in terms of improving energy efficiency. Let's create our dataset focusing on the fields:
- Energy Star
- Site Energy Usage Intensity (Site_EUI)
- Natural Gas Intensity (NGI)
- Eletricity Intensity (EI)
- Water Intensity (WI)
- Green House Gas Intensity (GHGI)
- Occupancy Per Sq Ft (OPSFT)
- Age
- Residential (1 or 0 if true or false)
We choose these fields as they should be independent of size of the building and therefore comparable across buildings.
Buildings = df_2016_2[df_2016_2['Property_Type'].isin(['Office','Multifamily Housing'])]
Buildings = Buildings.merge(pd.get_dummies(Buildings["Property_Type"])[["Multifamily Housing"]]
.rename(columns={"Multifamily Housing":"Residential"}),
left_index=True,
right_index=True)
columns = ["Energy_Star", "Site_EUI", "NGI", "EI", "WI",
"GHGI", "OPSFT", "Age", "Residential"]
Buildings = Buildings[columns]
Now since I will be working on this project over a few days I write this data to table so I won't have to constantly load and clean it again and again. Since I'm using the Google Cloud Platform, I'll using BigQuery for storing my data. This requires that I have credentials. I used the google-auth-oauthlib package and followed the instructions here to create a credentials json file:
from google.oauth2 import service_account
credentials = service_account.Credentials\
.from_service_account_file('./derby.json')
Next I installed pandas-gbq for connecting Pandas and BigQuery and set my credentials and project:
import pandas_gbq
pandas_gbq.context.credentials = credentials
pandas_gbq.context.project = credentials.project_id
Then I created a table raw_data in the database db_gb using the to_gbq function:
pandas_gbq.to_gbq(Buildings,
"db_gb.raw_data")
And were done! We can query the data from the BigQuery UI as shown below:
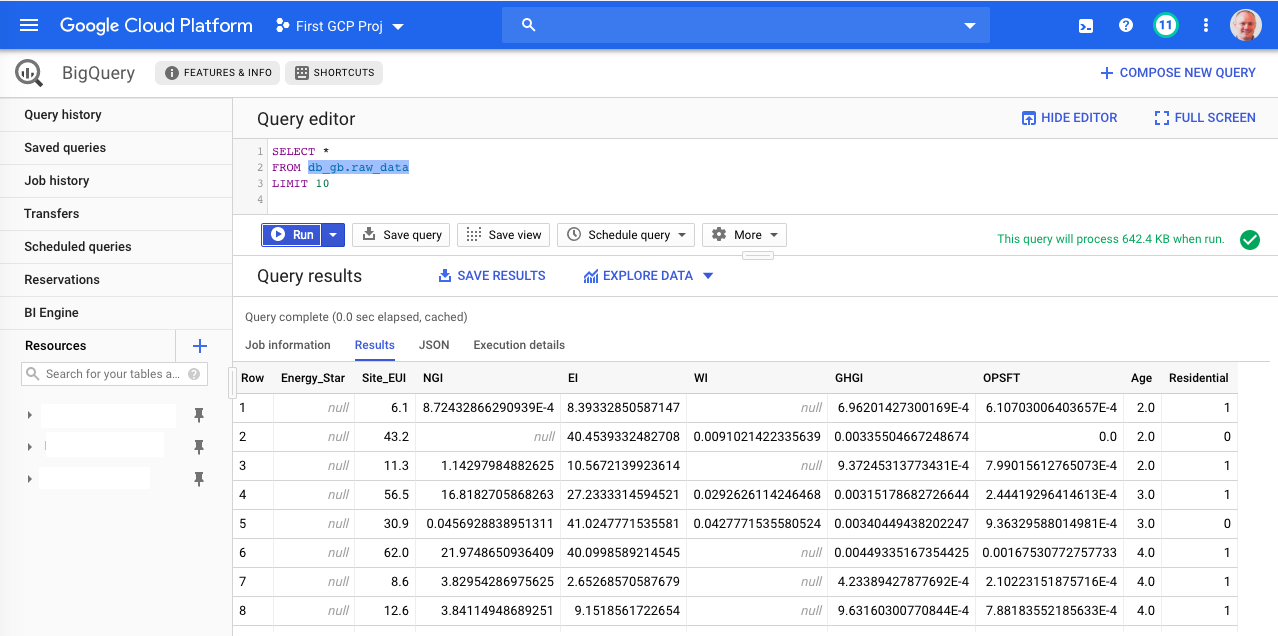
Let's move onto removing outliers.
Firs thing we need to do is to get the data from BigQuery as a Pandas dataframe. We use the read_gbq function from pandas_gbq:
X = pandas_gbq.read_gbq("""SELECT
Energy_Star,
Site_EUI,
NGI,
EI,
WI,
GHGI,
OPSFT,
Age,
Residential,
FROM
db_gb.raw_data
""")
We can then look at the distribution of values in the dataframe:
X.describe()
We can see again, large variations in the energy data, with most of it being between 0 and some fixed number with atleast one outlier. For example, the minimum age of a building is -2, which is absurd! We can also see from the varying "count" values that there are a significant number of missing values. Let's find out just how many buildings have atleast one missing value:
X_nna = X.dropna()
print("Total Buildings: {}".format(X.shape[0]))
print("Total Buildings without any missing data: {}".format(X_nna.shape[0]))
About half of the buildings have missing data! We'll first deal with removing outliers and then after that work on imputing missing values in the next post.
Let's plot the correlation matrix to see how correlated are features are on the all the buildings. Note that we first have to normalize the data.
from sklearn.preprocessing import StandardScaler
scaler1 = StandardScaler()
Xs = scaler1.fit_transform(X)
xs_df = pd.DataFrame(Xs, columns=X.columns)
fig, ax = plt.subplots(figsize=(8,6))
sns.color_palette("BuGn_r",)
sns.heatmap(xs_df.corr(),
linewidths=.5,
cmap="RdBu_r")

We can see that,
- Natural gas usage is fairly strongly correlated to green house emission rates which makes sense.
- Energy usage intensity is strongly correlated with natural gas intensity and greenhouse gas emissions. These make sense, since gas is a primary form of heating.
What doesn't make sense to me is that the energy star score is weakly correlated to any of the measures of energy, water or emissions. This is strange to me because a higher energy star score is supposed to reflect more efficient use of energy and water. Furthermore, the energy star score goes up (slightly) as the age increases which doesn't make sense as the I would expect older homes to be less energy efficient.
We can see how the results change when we only use building data that does not have missing values:
Xs_nna_df = pd.DataFrame(StandardScaler().fit_transform(X_nna),
columns=X_nna.columns)
fig, ax = plt.subplots(figsize=(8,6))
sns.color_palette("BuGn_r",)
sns.heatmap(Xs_nna_df.corr(),
linewidths=.5,
cmap="RdBu_r")

The previously mentioned correlations are now stronger, but there is still too weak a correlation between energy star score and energy or water usage for my liking. We'll have to dig deeper into the data to see if there are outliers that are affecting our correlation matrix.
Removing Visual Outliers ¶
In this section we'll be looking at box plots and scatter plots of various features against the Site_EUI variable to try to identify outliers in the data. We'll first look at box plots, separating out Age and energy metrics as they are very different scales.
plt.figure(figsize=(10,5))
sns.boxplot(data=X[["Energy_Star","Age","WI","GHGI",]])
plt.figure(figsize=(10,5))
sns.boxplot(data=X[["Site_EUI","NGI","EI"]])


We can see that there are a TON of outliers in all of the fields except Energy_Star and Age. Our strategy for removing the outliers will be to use scatter plots of various the metrics against the Site_EUI as their should be a natural relationship between them. For the purposes of this removing outliers let's focus on just NGI,EI,WI, and GHGI as we expect these correlated to Site_EUI:
sns.pairplot(X,
x_vars=['NGI','EI','WI','GHGI','Age','Energy_Star'],
y_vars=['Site_EUI'],
kind = 'reg',
size=5,
dropna=True)

Definitely a lot of outliers! We'll go through each of the individual scatter plots to find outliers each of the fields.
Let's first look at the scatter plot of natural gas intensity and energy usage intensity to see if we can observe outliers that may be affecting our correlation matrix. The reason we are doing so is that we suspect energy usage intensity should be highly correlated to natural gas intensity since natural gas is used for cooking and heating.
sns.pairplot(X,
x_vars='NGI',
y_vars='Energy_Star',
kind='reg',
size=5,
dropna=True)

We can see at least one extreme outlier! Looking at the box plot of values we can see that most of the values for NGI are under 100,000. Let's try that as starting point and remove values above 100,000 to see if there is a clearer relationship between the natural gas usage and EUI:
sns.pairplot(X.query("NGI < 100000"),
x_vars='NGI',
y_vars='Site_EUI',
kind='reg',
size=5,
dropna=True)

Still a significant number of outliers that need to be removed. We could use domain knowledge if we have it on what are reasonable range of values for NGI. Since I don't have that knowledge I experimented with different values and was able find a number that gave me a reasonable relationship:
sns.pairplot(X.query("NGI < 1e3 & Site_EUI < 1e3"),
x_vars='NGI',
y_vars='Site_EUI',
kind='reg',
size=5,
dropna=True)

We can see that buildings that have higher natural gas usage per sqft have a higher energy intensity and this makes sense!
We could repeat the same procedure for the other variables, but this can get tiresome searching for good filters. I recently found another way to get better values for filters which we'll go over next.
Removing Outliers With Isolation Forests ¶
An Isolation Forest is an unsuperised method that uses an collection of decision trees to identify outliers in a dataset. The algorithm works by exploiting that fact that outliers are rare and most datapoints that are normal have similar feature values. The algorithm is able to label data points into outliers and normal points by recursively generating partitions on the dataset through randomly choosing features and its splitting values. The partitions are recursively created until a single data point is in the partition or all the points in the partitions have the same value.
A diagram of the recursive partitioning is shown below:
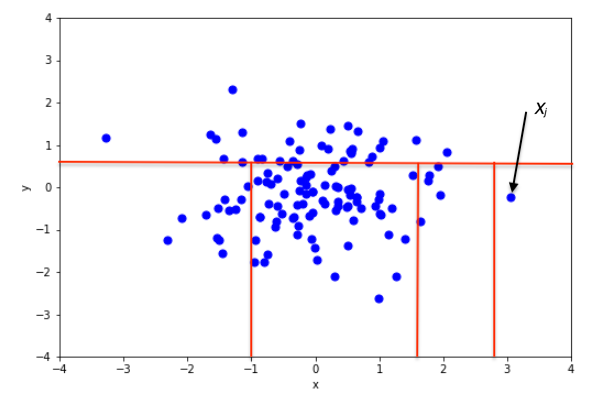 |
|---|
| From https://en.wikipedia.org/wiki/Isolation_forest |
This recursively partitioning can be respresented as a tree and the length of the path from the root to the terminal node can be treated as a measure of normality. Points that require relatively few partitions and have relatively a small length to their terminal node (such as $X_j$ above) are considered outliers. When a forest of trees says the average depth to isolate a datapoint is small it's then flagged as a outlier by the model.
Scikit-learn has an implementation of Isolation Forests that we will make use of to determine reasonable filters for outliers. One thing to notice is that there cannot be any missing values in the dataset when we fit the model:
from sklearn.ensemble import IsolationForest
iforest = IsolationForest().fit(X_nna)
I found that default settings in Scikit-learn worked quite well and didn't need to tune it all. We can now use that model to label points as outliers (-1) or normal (1) and the look at the scatter plot for the new feature values
X_nna["outlier"] = iforest.predict(X_nna)
X_noo = X_nna.query("outlier == 1").drop("outlier", axis=1)
sns.pairplot(X_noo,
x_vars=['NGI','EI','WI','GHGI','Age','Energy_Star'],
y_vars=['Site_EUI'],
kind = 'reg',
size=5,
dropna=True)

These look like much more reasonable relationships! Let's get the maximum values to find the filters for removing outliers:
X_noo.describe().iloc[-1]
We can use 140 as the upper bound for NGI and 180 for Site_EUI:
sns.pairplot(X.query("NGI <= 140 & Site_EUI <= 180"),
x_vars='NGI',
y_vars='Site_EUI',
kind='reg',
size=5,
dropna=True)

We can see a much clearer relationship of NGI TO Site_EUI, where there seem to be a cluster of buildings with linear relationship and a cluster that has no relationship and is vertical.
Note that we can use the restriction on the original dataset (X) without removing the nulls. We can do the same thing for EI:
sns.pairplot(X.query("NGI <= 140 & Site_EUI <= 180 & EI <= 55"),
x_vars='EI',
y_vars='Site_EUI',
kind='reg',
size=5,
dropna=True)

The relationship is less obvious, but we can see that buildings with higher electricity per square foot have a higher energy usage intensity.
Now we do the same for water usage intensity and EUI. While it might not seem obvious that water usage could be correlated with energy usage intensity, I'm thinking it may be becasue often water is used for heating and cooling.
sns.pairplot(X.query("NGI <= 140 | Site_EUI <= 180 & EI <= 55 & WI <= 1.4"),
x_vars='WI',
y_vars='Site_EUI',
kind='reg',
size=5,
dropna=True)

Interestingly, here we see a weaker, but still positive correlation, meaning buildings which use more water per square foot only have marginarly higher energy usage intensity.
Lastly we repeat the procedure for greenhouse gas emission intensity (GHGI), since I think that if a building is more energy intensive it would have a much larger carbon foot print. It turns out the filters already used were good enough and it didnt seem like there was too many outliers:
sns.pairplot(X.query("NGI <= 140 & Site_EUI <= 180 & EI <= 55 & WI <= 1.4"),
x_vars='GHGI',
y_vars='Site_EUI',
kind='reg',
size=5,
dropna=True)

Over all there are not too many outliers! I can live with the data as is and not remove any more data points.
Let's take a look at the box plots again:
X_noo_df = X.query("NGI <= 140 & Site_EUI <= 180 & EI <= 55 & WI <= 1.4")
plt.figure(figsize=(10,3))
sns.boxplot(data=X_noo_df[["Energy_Star","Age","EI"]])
plt.figure(figsize=(10,3))
sns.boxplot(data=X_noo_df[["Site_EUI","NGI"]])
plt.figure(figsize=(10,3))
sns.boxplot(data=X_noo_df[["WI","GHGI"]])



The box plots show that there are still a lot of outliers, but I don't want to remove too many data points, just the most egregious outliers. Let's look at each of the correlations to see how were doing with the realtionships:
sns.pairplot(X_noo_df,
x_vars=['NGI','EI','WI','GHGI','Age','Energy_Star'],
y_vars=['Site_EUI'],
kind = 'reg',
size=5,
dropna=True)

We can see these all make sense as mentioned before. The last correaltion Site_EUI vs Energy_Star which is somewhat nonlinear, but shows that as Enegery Star increases the site energy usage goes down and this makes sense!
It look's like EUI is very positively correlated to the green house gas emission intensity and natural gas usage intensity. The relationship between EUI is slightly less strongly correlated to electricity usage intensity and even less so with water usage intensity.
We can also see from the plot below that the site EUI was not very correlated to the year that the buildings were constructed. Most likely this is because so many were built around the same time period.
Now that we have removed some outliers we can visualize the correlation matrix to see if it makes more sense and gleam some insights into improving these building energy efficiency.
fig, ax = plt.subplots(figsize=(8,6))
sns.heatmap(X_noo_df.corr(),
linewidths=.5,
cmap="RdBu_r")

This is a much more belivable correlation matrix than the previous two we looked at!!
We can see that the Energy Star score is very negatively correlated with enery usage intensity, which make sense as the energy star score is a measure of energy efficiceny of the building. Furthermore the Energy Star score is negatively correlated with electricity, water, and natural gas usage intensity as well as green house gas emission intensity which makes sense. Additionally, we see that Energy Star Score is independent of occupancy per square foot which makes sense since it is a function of the building's efficiency and not the people inside of it.
I'm going to again write the results of outlier removeal to BigQuery so as not to have recompute everything again when I come back to this project for the next post. This time however I will create new table by filtering on the raw data table:
from google.cloud import bigquery
client = bigquery.Client(project = credentials.project_id,
credentials = credentials)
job = client.query("""
CREATE TABLE db_gb.no_outlier_data
AS
SELECT
Energy_Star,
Site_EUI,
NGI,
EI,
WI,
GHGI,
OPSFT,
Age,
Residential,
FROM
db_gb.raw_data
WHERE
(NGI <= 140 OR NGI IS NULL)
AND (EI <= 60 OR EI IS NULL)
AND (WI <= 1.4 OR WI IS NULL)
AND (Site_EUI <= 180 OR Site_EUI IS NULL)
""")
job.result()
We can see the total number of buidlings we have removed as outliers:
num_rows = client.query("SELECT COUNT(1) FROM db_gb.no_outlier_data")
for row in num_rows.result():
print("Total Buildings in without ouliers: ", row[0])
And compare to the oringal number of buildings:
print("Total Buildings in original data: {}".format(X.shape[0]))
We can see that we removed 669 buildings or a little less than 7%, which is a little high, but given this is self reported data it's not entirely unreasonable.
Recommendations & Next Steps ¶
In this first of a series blog post we analyzed the energy usage of buildings in New York City. From the final heat map of the correlation matrix we can see that the Energy Star score is negatively correlated with enery usage intensity. This makes sense as the energy star score is a measure of energy efficiceny of the building. The energy usage intensity has a strong positive correlation to the natural gas usage intensity. We can see that natural gas usage intensity and electricity usage intensity are uncorrlated. This implies we could replace one with the other. Therefore reducing natural gas consumption or replacing it with electricity could be the best answer to reducing energy usage intensity and green house gas emissions. It should also be noted that year the residence was built did not have any correlation with energy usage intensity. This is probably due to the fact that the majority of residential buildings in New York City were built in a similar time period and before energy efficiency was a priority.
Since natural gas usage intensity is most highly correlated with energy usage intensity reducing it could improve building energy efficiency and reduce green house gas emissions (so long as the buildings' electricity comes from a clean energy source or atleast one with less emissions than natural gas). Some ways to reduce natural gas consumption include:
- Investing in more efficient heating and cooling services or slightly reducing the usage of either heating or cooling during the day when most people are not home. This is especially important in large buildings as HVAC systems have a larger volume of air to heat/cool.
- Another option is to reuse waste heat, such as reusing the vented air from electric clothes dryers, however, filtering and the air will be necessary and could alter the cost effectiveness of this approach.
- Replacing gas powered appliances such as stoves with more efficient electric ones is another option. However, the source of electric power should also be considered to weigh the overall energy efficiency and enviromental impact.
- Another option is to replace gas powered water heaters by solar powered water heaters. While solar powered water heaters are not as cost effective in moderate climates, the presence of numerous roof top water tanks on New York City buildings may help make this option more financially competitive. At the very least, it suggests that having roof top water tanks for solar powered water heaters is structurally possible, where as with individual houses this may not be the feasible.
- In addition, buying energy efficient refrigerators and dryers is also important as these are two of the largest energy consumers in ones home.
We saw that there were a lot of fields in the dataset with missing values. In the next blogpost we will go over the steps to how to impute these missing values.