Contents Link to heading
Introduction
Introduction To Function Approximation
Introduction To Regression
Linear Solvers For Least Squares Regression
Cholesky Factorization For Normal Equations
Singular Values Decomposition
Controlling For Overfitting With Regularization
Implementation in Scikit-learn
A Touch Of Recommendation Systems
Where To Go From Here
Introduction Link to heading
In this blogpost we’ll go over applications of numerical linear algebra in machine learning starting out with regression and ending with modern recommender systems! Numerical linear algebra (and numerical analysis more generally) was one of thoses courses that I learned, thought was boring and never wanted to study again. Only with maturity that comes with age (and a PhD) was I able to understand and appreciate the true power of numerical linear alebra. Infact understanding (distribued) linear algebra is probably one of the most important and useful tools I have ever learned. It has allowed me to contribute to open source libraries for scientific computing and understand how big data and machine learning systems work. The reason why numerical linear algebra is so important is because it allows us to approximate functions. In scientific computing and machine learning one is interested in how to approximate a function . Numerical analysis and statistics concerns itself with how good is our approximation to ?
Traditionally algorithms in Numerical Linear Algebra are taught/learned in Matlab for easy learning, but written for production Fortran and C/C++ for high performance. The fields of Data Science, Machine Learning and Artifical Intelligence have a seen recent boom and given a new life and applications to these algorithms. These fields lean more to using Python (though R is often used as well) as the primaty programming language, but make heavy use of wrappers to BLAS and LAPACK libraries written in Fortran and C/C++.
Many Data Scientists and Machine Learning Researchers also heavily make use of Jupyter notebook as a tool for rapid prototyping and writing experiments in Python (though it also allows for the use of other languages likes R, Julia and Scala). Jupyter notebook is as an interactive envrionment for computing that runs in your web browser and is very similar to Mathematica’s notebook. The fact it runs in a web browser is quite convenient as it will allows users to easily work on a remote computer without any complicated set up. See this post about how to get set up with Python & Jupyter notebooks on Google Cloud with all the dependencies installed for this post.
Introduction To Function Approximation Link to heading
Let’s now move onto function approximation. One learns in Calculus to represent smooth functions about some point using special polynomials called power series or Taylor series:
We can find the coefficients to the series by the equation,
We observed that there is a radius of convergence such that within (one should test the end points too) the series converges to uniformly and outside that it does not necessarily converge to .
We then learned that we can approximate our function with the finite degree polynomial,
We can then use that approximation to perform calculations on our function that might not have been possible otherwise. The most memorialble for me being learning how to integrate a Gaussian. Though in practice numerical integration is usually perferred for finite integrals.
Power series were originaly developed to approximate solutions to differential equations. As science and engineering progressed the differential equations become more complicated and harder to solve. Other approximation methods were invented like Fourier Series:
We remark that the functions and form an orthogonal basis for the Hilbert Space . Coefficients for the approximations are determined projecting the function onto the basis functions:
The convergence of the Fourier series is much subtle issue. While the Taylor series was guaranteed to converge uniformly, the regularity conditions imposed to achieve this were quite strong. The class of functions in is quite broad and depending on the regularity conditions of our specific function we will get different modes of convergence.
Let’s derive the second equation for by using a “projection” onto the basis function ,
Which finally becomes,
The above example illustrates the two steps in our approximation methods:
Projecting the function (or its values) onto a finite dimensional space
Solving for the co-efficients corresponding to each of the basis functions
The last step is not usually as easy as the above example was and often requires solving a system of linear equations:
The need to solve a system of linear equations occurs most often because the basis for our finite dimensional space is not orthogonal. If the basis were orthogonal, then the matrix would be diagonal and we could be invert it by hand, leading to equations like the Fourier coefficient equations.
Each of these steps in our approximations methods introduces their own errors:
The error in your model approximation.
The error in solving the linear system of equations.
The first error best summarized in the bias-variance trade off (see Section 2.2 in this book as well). By this I mean that by assuming that our function has only features we introduce a bias into our model and as we increase the number we will most likely increase the variance in our model. The second error is due to rounding errors and numerical stability. We won’t touch on either of these topics too much, but mention them for completeness.
With the advent of the computer and seemingly cheap and unlimited computational resources numerical methods like finite difference and finite element methods were invented to approximate solutions to differential equations. The finite element method is one that is particularly dear to my heart and has concepts that have proved useful in understanding models in statistics and machine learning, particularly, Generalized Addative Models.
In the next section well go into the basics of Linear Regression models which is a subset of the larger class of Generalized Additive Models.
Introduction To Regression Link to heading
Linear regression is generally the first statistical modeling technique one learns. It involves relating some target that is a continuous random variable to “features” represented as a vector: using coefficients . The coefficient is called the “intercept.” The features can have continuous and non-negative integer values and are generally considered to be non-random. The relationship between the target values and features values is described by the model,
Where are independent and normal distributed with mean 0 and variance 1 and are the unknown co-efficients. The fitting the linear regression model then becomes,
Fitting the model then becomes finding the cofficients that best approximates for . This model is often called ordinary least squares and converges in probability.
In general we will have many distinct measurements corresponding to values that are collected into a training set, . This can be represend in the form ), where is the Design Matrix and is the vector corresponding of target values. We also have a test set, . This can be represend in the form ), where and is the vector corresponding of target values. The training set is the set of points we use to determine and the testing evaluating the performance of our model. For ease of notation we will simply drop the +1 from the , but the reader should always remember there is an intectept. Let’s make things concrete using some example data.
The data we will use (data.csv) comes from the NYC Mayor’s Office of Sustainbility and contains energy efficiency measurements of multi-family housing units in New York City. We will use some of the measurements to predict the Green House Gas Emissions of the buildings, you can read more how this data was cleaned here. The file has the following columns:
NGI: Nautral Gas Use Intensity (kBtu/ft 2 )EI: Electricty Use Intensity (kBtu/ft 2 )WI: Water Use Intensity (kga/ft 2 )Site_EUI: Site Energy Usage Intensity (kBtu/ft 2 )GHGI: Green House Gas Emissions Intensity (Metric Tons CO2e / ft 2 )
We can import the data using Pandas which gives us a fast way to read in data from csv documents:
import pandas as pd
#columns we care about
cols = ['NGI','EI','WI','Site_EUI','GHGI']
# read the data
df = pd.read_csv("data.csv",
usecols = cols)
#view the first 5 lines
df.head()
| Site_EUI | NGI | EI | WI | GHGI | |
|---|---|---|---|---|---|
| 0 | -0.037249 | -0.016434 | -0.012849 | -0.104832 | -0.037384 |
| 1 | -0.037921 | -0.017372 | -0.007096 | -0.040264 | -0.037782 |
| 2 | -0.033047 | -0.013440 | 0.019025 | -0.047608 | -0.031731 |
| 3 | -0.034623 | -0.012073 | -0.026548 | -0.118878 | -0.034398 |
| 4 | -0.033804 | -0.013676 | 0.008066 | -0.077564 | -0.032913 |
We split out dataframe into a training and test set:
df_test = df.sample(frac=0.25, random_state=42)
df_train = df.drop(df_test.index, axis=0)
Then our target variable then is the GHGI and design matrix becomes the rest of the columns:
import numpy as np
# Design matrix
X = df_train[['NGI','EI','WI','Site_EUI']].values
# Target vector
y = df_train[["GHGI"]].values[:,0]
# Design matrix
X_test = df_test[['NGI','EI','WI','Site_EUI']].values
# Target vector
y_test = df_test[["GHGI"]].values[:,0]
print("X = \n", X)
print()
print("X.shape = ", X.shape)
print()
print("y = \n", y)
print()
print("X_test.shape = ", X_test.shape)
X =
[[-0.0164345 -0.01284852 -0.1048316 -0.0372486 ]
[-0.01737222 -0.00709637 -0.04026423 -0.03792081]
[-0.01344039 0.01902526 -0.04760821 -0.0330473 ]
...
[-0.01034947 -0.03023676 0.00994682 -0.03592519]
[-0.00979158 -0.03166883 -0.00486112 -0.0356311 ]
[-0.00874449 -0.02223016 -0.05749552 -0.03100967]]
X.shape = (3702, 4)
y =
[-0.03738401 -0.03778169 -0.03173064 ... -0.03306691 -0.03265591
-0.03082855]
X_test.shape = (1234, 4)
and are now a NumPy matrix and array respectively and the same for and . NumPy is Python library that has highly optimized data structures and algorithms for linear algebra. Infact, Pandas is written on top of NumPy.
We can then look at the relationship or correlation each of the features has on the target variables by looking at their scatter plots using a function I wrote:
from plotting import plot_results
%matplotlib inline
plot_results(df_test)
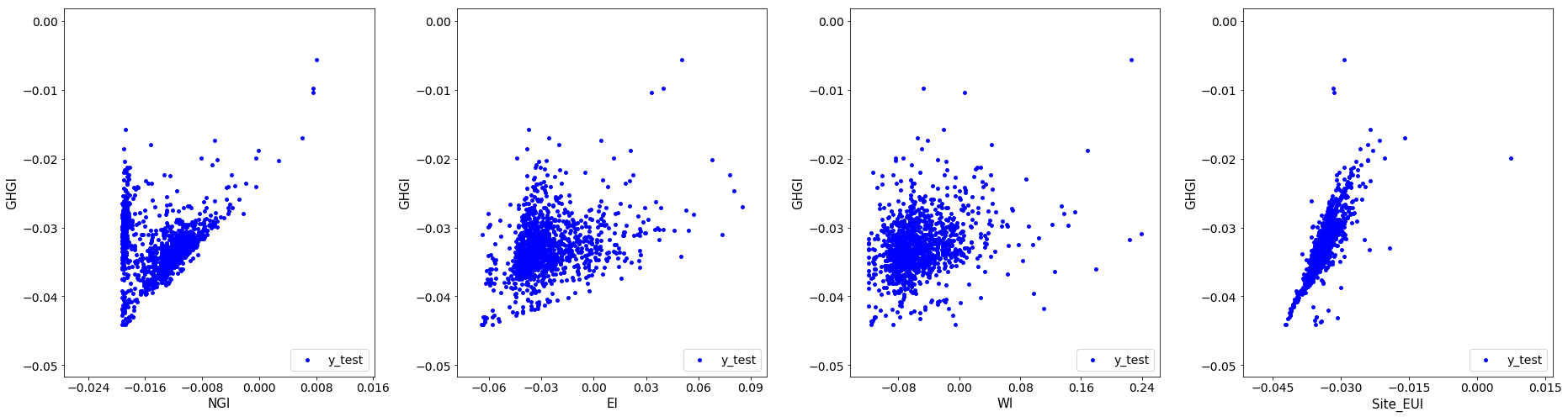
These scatter plots show us the correlation between GHGI and the different features. The far panel on the right shows us that as we increase Site_EUI on average we see GHGI increase linearly. This makes sense as the more energy a building uses the more green house gas it produces. The same is true of natural gas (NGI) as it is used for heating or cooking. Therefore if this goes up so should our green house gas emissions. Less intuitive may be electricity usage. We might not expect that as our electicity usage increases our green house gases increases, however, this could be due to the fact the source of the electricity comes from gas or coal. That fact this is less intuitive could also be why the shape is less linear than Site_EUI. The amount of water we use shoul not effect the green house gas emissions (maybe for heating hot water). This realiztion is displayed in the scater plot for WI as it does not show any distinct pattern.
Let’s now return to the linear regression. Our goal is to approximate the target variable with a function . This function is a linear combination of our features,
We find the solution vector or coefficients by minimizing the cost function ,
Mininmizing is equivalent to setting the . We can expand the cost function,
Taking the gradient of both sides we then have (for a review on matrix calculus see here),
Setting the above equal to zero yields the linear system of equations,
The above formulation is the so-called “Normal Equations”. We can rewrite them as,
Where and . When the features have been scaled (as we have assumed), the matrix is the covariance matrix
The vector is the projection of the target values onto the finite dimensional space that is spanned by the features. Defining the residual r as,
Then we note is the same thing as saying,
Or the solution is value such that the residual is orthogonal to our feature space or the residual is statistically uncorrelated with any of the features.
The covariance matrix is symmetric and positive definite, but if the two features are highly correlated then two rows in the matrix will be nearly identical and the matrix will be nearly singular. Statistically, having correlated features is bad since it makes it hard to determine the impact on any one feature has on the target. Numerically, having correlated features is bad because the condition number of the covariance matrix explodes. The reason is that the condition number is definted as,
Where are the singular values from the singular value decomposition. As the matrix becomes more singular , forcing the . We remark that the condition number affects not only the accuracy of your solution, but also the stability of the solvers, see Lecture 12.
There are two we will go over about solving the over-determined system of equations :
Solving the Normal Equations using the Cholesky Decomposition
Solving the linear system using the Singular Value Decomposition
However, one can also solve the Normal Equations using an LU factorization or the original system with the QR factorization.
Linear Solvers For Least Squares Regression Link to heading
See Lecture 11 for more detailed discussions.
Linear Solver 1: Cholesky Decomposition Of Normal Equations Link to heading
Let’s first solve the Normal Equations:
Our covariance matrix is symmetrix positive definite we can use the Cholesky decomposition:
where is an lower triangular matrix. To solve the system from the nomrmal equations then becomes,
Which we can rewrite as first solving,
Then solve,
As is an lower triangular matrix each of these linear system of equations is simple to solve and the forward/backward substitutions made to solve them are backwards stable.
Let’s try this out by first analyzing the covariance matrix
# Build the covariance matrix
X_t = X.transpose()
S = X_t.dot(X)
print("S = \n", S)
S =
[[ 0.74547278 1.35358196 2.7794211 1.72619886]
[ 1.35358196 4.09897316 5.16118203 3.39404027]
[ 2.7794211 5.16118203 16.53112563 6.69851448]
[ 1.72619886 3.39404027 6.69851448 4.2625346 ]]
Let’s take a look at the eigen values to understand the condititioning of our matrix
eigs = np.linalg.eigvals(S)
print(eigs)
[22.1809954 2.73222512 0.03890524 0.6859804 ]
cond_num = np.sqrt( eigs.max() / eigs.min())
print(f"Condition number = {cond_num}")
Condition number = 23.87736746652693
The eigenvalues are all positive and the condition number are not too big which is good!
We will now be using many SciPy function calls. SciPy is a sister Python library with Numpy and supports many scientific algorithms. SciPy’s linear algebra routines expand on NumPy’s and even allow for use sparse matrices and vectors. SciPy acts a wrappers around LAPACK, indeed the eigenvalue calculator directly calls LAPACK’s eigenvalue decomposition.
Let’s now perform the Cholesky Decomposition using SciPy:
from scipy import linalg
# Perform the Cholesky Factsaorization
L = linalg.cholesky(S, lower=True)
L
array([[0.86340766, 0. , 0. , 0. ],
[1.56772058, 1.28110317, 0. , 0. ],
[3.21912954, 0.08936547, 2.48200412, 0. ],
[1.99928602, 0.2027303 , 0.0984836 , 0.46324014]])
We can check to make sure that :
L.dot(L.T)
array([[ 0.74547278, 1.35358196, 2.7794211 , 1.72619886],
[ 1.35358196, 4.09897316, 5.16118203, 3.39404027],
[ 2.7794211 , 5.16118203, 16.53112563, 6.69851448],
[ 1.72619886, 3.39404027, 6.69851448, 4.2625346 ]])
Then use the matrix to solve the normal equations using SciPy’s solve_triangular (which solves a lower/upper linear system). This function directly calls LAPACK’s implementation of forward/backward substitution:
# solve for the coefficents
z = linalg.solve_triangular(L, X_t.dot(y), lower=True)
omega = linalg.solve_triangular(L.T, z, lower=False)
print(f"omega : {omega}")
omega : [-0.2376972 0.03247505 0.01313829 1.02531297]
We can now get the predicted values from
on the test set and plot the results against the true values y_test:
# Get the in sample predicted values
df_test["y_ols"] = X_test.dot(omega)
plot_results(df_test, 'y_ols')
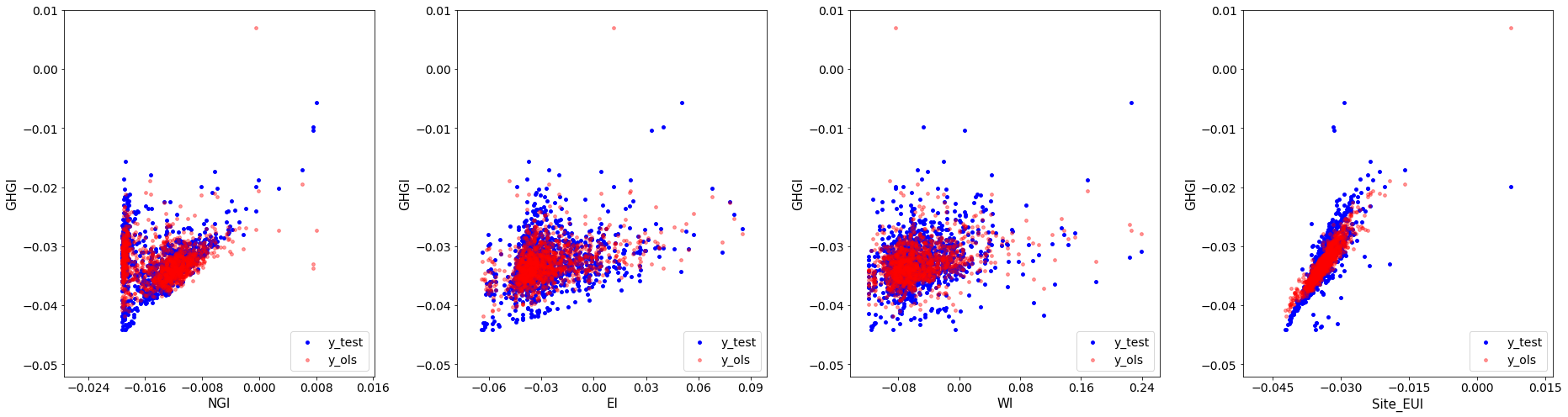
Not bad! Let’s move onto solving the system of equations with the singular value decomposition. I should note SciPy implements a Cholesky solver that directly calls LAPACK’s routine.
Linear Solver 2: The Singular Value Decomposition (SVD) Link to heading
Let’s solve the overdetermined system of equations,
using the Singular Value Decomposition (SVD):
Where and are unitary matrices and is a diagonal matrix with the singular values along the diagonal. We can substitute in the SVD into our system of equations to obtain,
We then transform this to a system of equations:
and
The last system of equation can be transformed using the fact is unitary ( ):
We can then solve the original system of equations by
Finding the SVD of the Design Matrix then solve,
Inverting the diagonal matrix to solve
Perform the matrix-vector multiplication:
We can perform the SVD using SciPy (which to no surprise calls LAPACK’s routine):
U, Sig, Vt = linalg.svd(X, full_matrices=False)
We can then look at the shapes of each of the resulting matrices:
U.shape, Sig.shape, Vt.shape
((3702, 4), (4,), (4, 4))
And then perform the steps described above to find ,
z = (1 / Sig) * U.transpose().dot(y)
omega = Vt.transpose().dot(z)
print(f"omega : {omega}")
omega : [-0.2376972 0.03247505 0.01313829 1.02531297]
The solution via Cholesky Factorization and the SVD have the same solutions!
One very nice thing about linear regression is that it is very easy to interpret. In linear regression, the coefficients tell us how much an increase in one unit of the feature increases the target variable by one unit. Therefore increases in the sites energy usage intensity (Site_EUI) increase the GHGI the most and intuitively this makes sense. However, the model is also telling us that the increases in natural gas usage (NGI) decrease the GHGI which doesn’t make sense. This most likely happened because the features are correlated (see off diagonal values in covariance matrix
) or because the model was over-fitting, i.e. giving to much weight to a specific feature.
Controling For Overfitting With Regularization Link to heading
Often times a linear regression will give us good results on the training set, but on very bad results on another independent (test) dataset. This is an example of overfitting our model. We can control for overfitting our model by introducting regularization of the form,
where . For this is called Ridge Regression and for it is called Lasso Regression. Ridge Regression serves to control for over-fitting by shrinking the parameters as increases. Not all individual parameters must shrink as increases, but in aggregate decreases. We note that both methods seek to reduce the variance in model, and subsequently increase the bias.
Remark: In neither method do we consider penalizing the value .
In the case of Ridge Regression we can view the cost function as,
Which after expanding the values and setting the derivative to zero yields,
We can see that the regularization term acts to remove the singularity from the covariance matrix if there is correlation among features. Using the SVD we arrive at:
We can transform the last equation to the system of equations:
with the system corresponding equation which can be rewritten using the unitary property of as the matrix-vector multiplication:
The matrix, is diagonal and can be inverted by hand. This gives us a way of solving the problem for Ridge Regression for a given :
Finding the SVD then solve
“Invert” the matrix to obtain
Perform the matrix-vector multiplication
We remark we can combine the 2. and 3. to obtain the formula:
And then our predictions become:
As you may have learned the matrix is unitary so it acts a change of basis transformation and the matrix is a diagonal matrix that either shrinks or elongates along this new basis as shown below:

The values along the diagonal of take the form,
From this formulation acts to shrink the influence of low frequency singular vectors ( small) more than it does high frequency singular vector ( large)!
Let’s see how our code will look for solving the Ridge Regression problem using the SVD.
# using function annotations in Python 3
# (see, https://www.python.org/dev/peps/pep-3107/)
import scipy as sp
def ridge_svd(
X : np.ndarray,
y : np.ndarray,
reg_param : float = 1.0
) -> np.ndarray:
"""
Solves the Ridge Regression problem using the SVD.
Params:
-------
X : The matrix of features
Y : The target vector
reg_param : The regularization parameter
Returns:
--------
omega : The array of coefficent for the solution
"""
# compute the SVD
U, Sig, Vt = sp.linalg.svd(X, full_matrices=False)
# for Sigma^{T} Sigma + \lambda (this is an array)
Sig_plus_reg = Sig * Sig + reg_param
# find z by "inverting" the matrix and then get omega
z = (1.0 / Sig_plus_reg) * Sig * U.T.dot(y)
omega = Vt.T.dot(z)
return omega
Let’s test this with which should give us the least squares regression solution:
print("omega: ", ridge_svd(X, y, 0.0))
omega: [-0.2376972 0.03247505 0.01313829 1.02531297]
It does! Let’s try adding a little regularization and see what happens.
omega = ridge_svd(X, y, 0.1)
print(f"omega: {omega}")
omega: [0.14161464 0.07955296 0.03040791 0.78857811]
We can see that adding regulaization shrank the last feature, i.e. (Site_EUI) and made turned the coefficient for NGI positive which makes sense! Let’s take a look at the results:
df_test["y_ridge"] = X_test.dot(omega)
plot_results(df_test, 'y_ols', 'y_ridge')
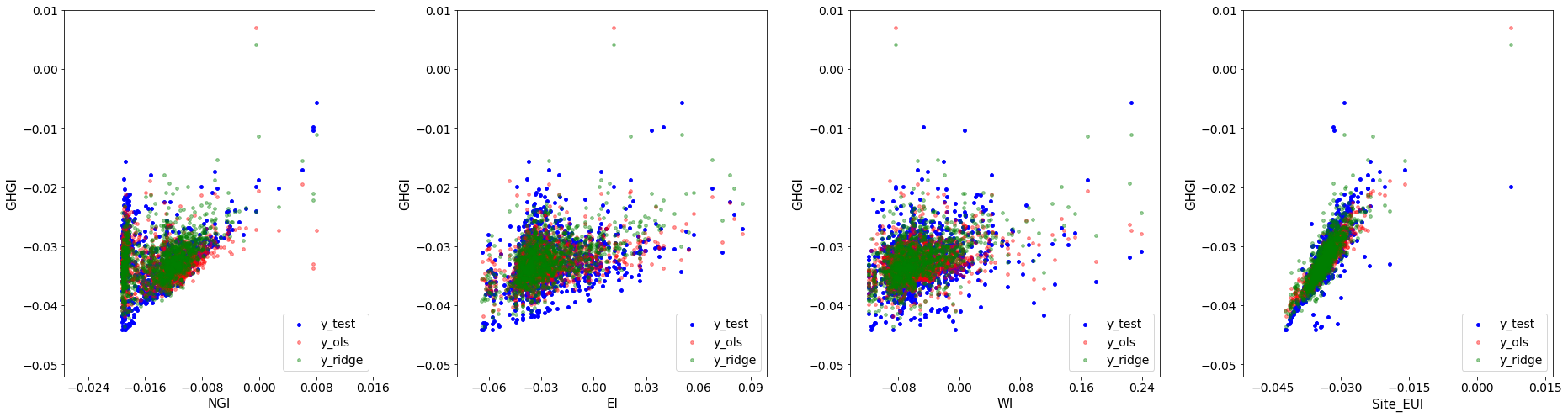
It’s hard to say whether least squares or ridge regression is better from these figures, but the coefficients for Ridge Regression make much more sense. Notice that I have left out how to find the regularization parameter . That topic is out of scope for this post. However, for reference, the best value for is often chosen via cross-validation, see these slides for more information.
Implementation In Scikit-Learn Link to heading
Scikit-Learn is the industry standard open source machine leanring library in Python. As it is open source we can easily see how the developers wrote their linear sovlers by going to the library’s GitHub.
For regression, Scikit-learn mostly acts as a wrapper around Scipy which act as a wrapper to BLAS/LAPACK. The regular linear regression Scikit-Learn implementation utilizes Scipy’s least square solver, which if the matrix is dense calls BLAS/LAPACK. If the matrix is sparse then it calls SciPy’s sparse least squares solver which uses least squres with QR factorization LSQR. Note that while may be a large sparse matrix, the covariance matrix is typically quite small and dense.
For ridge regression, unless the user specifices the linear sovler to use then if the intercept is needed Scikit-learn solve the linear system with the Stochastic Average Gradient method, otherwise it uses the Cholesky Decomposition for dense matrices and Conjugate Gradient method for sparse matrices. Although, all the algorithms are written for dense or sparse matrices. The congugate gradient method makes use of SciPy’s Sparse CG function which does not need to explicitly form the matrix, but rather only needs its action on a vector making it extremely efficient for sparse matrices. If any of these methods fail, the least square QR solver is used.
A Touch Of Recommendation Systems Link to heading
Recommendation systems have become very popular and are one of the best examples of Machine Learning that we interact with daily, i.e. Amazon and Netflix. One popular technique for making recommendations is called Alternating Least Squares.
The idea is that we have some table of ratings of items by users as shown below:

However, not all users will have rated all items and we want to predict how a user may feel about an item they have not rated. This is how recomendations happen, through the prediction of how a user might rate an item they have not seen before!
Let’s for example take the idea of recommending movies to users of a webservice. The idea is we want to say a given user has some preference on a movie by the perfence of the generes that make up the movie. For simplicity let’s say movies are a combination of the genres (so-called latent factors in machine learning):
- Horror
- Action
- Comedy
Then we can write a user’s preference as well a movie as a linear combinatin of these genres:
The above shows how Sally would rate “Weekend at Bernies” given that she likes films involving Horror and Action, but dislikes action films and that “Weekend at Bernies” is a little bit of action and a lot of comedy. If we label as user ’s rating of movie , then the inner product of the vector of movie coefficients and user preferences is :
We can then factorize the review matrix into a product of movies and users as depicted in the diagram above,
If and we have latent factors that make a movie then the movie genres are and user preferences are . How do we find the coefficient for each user and each movies, i.e. how do we find the matrices and ?
The idea is we can set up a cost function almost like Ridge Regression and minimize with respect to and :
Where is the Frobenius Norm. How do we minimize for both and ? Well one way is to:
Randomly initialized and then
Fix and solve for such that
Fix and solve for such that
Repeat steps 1 and 2 until convergence or max iterations reached
At each stage in 1. and 2. you are updating the choice and and by essentially solving a Least Squares Ridge Regression problem for and . The alternating nature of this iterative algorithm gives rise to its name Alternating Least Squares! Some links to good references for Alternating Least Squares below.
Where To Go From Here Link to heading
We’ve gone over a few topics in this blogpost and I want to supply the reader with some links for more information on the topics discussed.