SQL Wars: Comparing Relational Databases¶
Table of contents¶
Introduction¶
Coming from a computational science/applied mathematics background many of the ideas of data science/machine learning are second nature to me. One thing that was very new to me was creating and manipulating databases. In computational science we don't really deal with databases and I/O is something to avoid as much as possible because it limits performance. Therefore, in this blog post I'll be going what I have learned about SQL databases, i.e. what they are, how to set them up, and how to use them.
In this post I'll be focusing on two SQL implementations,
and
- PostgreSQL and Python's interface to it sqlalchemy and psycopg2.
Another option, and probably the most popular option, is MySQL. However, I wont be talking about MySQL in this post.One thing that was particularly helpful with SQLite was the DB Browser for SQLite which is a GUI for SQLite databases. A similar tool with more features for PostgreSQL that is pgAdmin, but I haven't used it too much. For now, let's first start out discussing SQL, relational databases and the client-server model for databases.
Preliminaries¶
SQL¶
SQL stands for Structured Query Language. It is a domain specific language used in programming to deal with data that is stored in a relational database. SQL is designed for a specific purpose: to query data contained in a relational database. There are plently of good references on how to learn SQL query commands, two that I used were,
However, SQL queries are not not what I intend to cover in this post. Instead, I would like to look at how one can create and interact with different implementations of SQL databases. And specifically how to do this using Python. There are many different implementations of SQL: SQLite, Oracle, MySQL, PostgreSQL, etc. The basic operations on SQL databases that are common to all the implementations are described in the acronym, C.R.U.D.:
- Create: How to create a database and tables.
- Read: How read from a table in a database.
- Update: How to update the values in a table in the database.
- Delete: How to delete rows from a table in the database.
A sequence of database operations that satisfies the A.C.I.D properties can be perceived as single logical operation on the data, is called a transaction. A.C.I.D is an acronym for set of properties relating to database transcations. The properties are,
- Atomicity: The requirement that each transaction be "all or nothing." This means that if one part of the transaction fails, then the entire transaction fails, and the database state is left unchanged.
- Consistency: Consistency ensures that any transaction will bring the database from one valid state to another and that changes that have affected data were only completed in allowed ways. Consistency does not however, guarantee the correctness of the transcation.
- Isolation: This property ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed sequentially, i.e., one after the other
- Durability: Durability ensures that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors.
As we will see, most of the differences between working with the two implementations will be in how we create the databases. The queries will be relatively the same, but the libaries we use to interact with the databases will be different depending on the SQL implementation. Let's now talk about the relational database model.
Relational Database Model¶
This model organizes data into one or more tables (or "relations") of columns and rows, with a unique key identifying each row. Rows in a table can be linked to rows in other tables by adding a column for the unique key of the linked row (such columns are known as foreign keys). Most physical implementations have a unique primary key (PK) for each table. When a new row is written to the table, a new unique value for the primary key is generated; this is the key that the system uses primarily for accessing the table.
The primary keys within a database are used to define the relationships among the tables. When a primary key migrates to another table, it becomes a foreign key in the other table. This can be seen below where the primary key, ID, in the School Table becomes the foriegn key, School ID, in the Student Table:
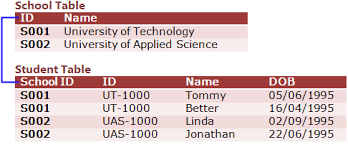
When each cell can contain only one value and the primary key migrates into a regular entity table, this design pattern can represent either a one-to-one or one-to-many relationship. A one-to-one relationship exists when one row in a table may be linked with only one row in another table and vice versa. A one-to-many relationship exists when one row in table A may be linked with many rows in table B, but one row in table B is linked to only one row in table A. The above diagram of relationship between the School Table and the Student Table is an example of a one-to-many relationship. There is also a many-to-many relationship, but this is more complicated and we won't discuss it further. The example I will work below will involve a one-to-many relationship.
Client-Server Model For Databases¶
The client-server model is a distributed application structure that partitions tasks or workloads between the providers of a resource or service, called servers, and service requesters, called clients. The resource/service in the case of a database is the data stored in it. Often clients and servers communicate over a computer network on separate hardware, but both client and server may reside in the same system. A server host runs one or more server programs which share their resources with clients. A client does not share any of its resources, but requests a server's content or service function. Clients therefore initiate communication sessions with servers which await incoming requests.
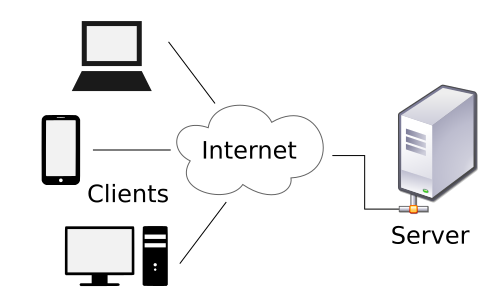
Now that we got that basic information under our belt let's get started with SQLite first!
SQLite¶
SQLite was the first relational database that I learned. It's fast, lightweight and filebased. In contrast to many other database management systems, SQLite is not a client–server database engine. Rather, it is embedded into the end program. SQLite stores the entire database (definitions, tables, indices, and the data itself) as a single cross-platform file on a host machine. SQLite is also embedded into Python naturally with sqlite3 which we will be covering in this post.
Let's get started with C.R.U.D. for SQLite with Python:
Creating A SQLite Database¶
First thing we need to do is import sqlite3:
import sqlite3
Then we need to connect to our database using the command,
conn = sqlite3.connect("database_name")
Let's do this below, calling the database MyFirstDatabase.db,
conn = sqlite3.connect("MyFirstDatabase.db")
The connect function acts to make a "connection" to the database stored in the file MyFirstDatabase.db. If the file does not exist, then it will be created automatically. It may seem a little silly to "connect" to a file that is on our computer, but sometimes the database can reside on a different computer and the phase makes more sense. We then use the cursor() function to "open" the database:
cur = conn.cursor()
Every interaction we make with our database through python will now occur through the cursor object cur.
Say, we now wish to create a table within the database called Person which contains the name, id, and salary of all employees with our company. We note that name will be of type TEXT, which is SQLite's version of a string, while id and salary will be of type INTEGER. Since each person will be uniquely identified with their id we make this the PRIMARY KEY.
The SQLite command to create this table if it doesn't already exist is,
create_table = """CREATE TABLE IF NOT EXISTS Person
(
name TEXT,
id INTEGER PRIMARY KEY,
salary INTEGER
)"""
We excute this command on the SQLite database using the sqlite3 function execute():
cur.execute(create_table)
Note: We can write SQL commands using single qoutation marks ('...'), double qoutation marks ("...") or as above with three double qoutation marks("""..."""). The latter is perferable for SQL commands for two reasons:
- We can continue the command onto another line without the need for a backslash.
- When using single quotation marks we would have to write a SQL string using backslashes before the single qoutations, for example:
This isn't necessary with double quotation marks or three double qoutation marks.'name = \'Bob\' '
Now we'll create another table called Emails which contains all the employee emails. The table will contain employee_id which is an INTEGER, email which is of type TEXT and email_id which is an INTEGER. The email_id will be our PRIMARY KEY since it is an integer that uniquely identifies each row. The FORIEGN KEY in this table is then employee_id since it is the PRIMARY KEY in the Person table. Since employees can have more than one email address this is an example of a one-to-many relationship. The command to create the Emails table is then,
create_table = """CREATE TABLE IF NOT EXISTS Emails
(
email_id INTEGER PRIMARY KEY,
employee_id INTEGER FORIEGN KEY REFERENCES Person(id),
email TEXT
)"""
Notice how after we declare our foriegn key we have to say what the primary key in which table it references. Now we can execute the command:
cur.execute(create_table)
Now that we have created the tables can start to insert values into them. We use the SQL command INSERT to insert a new row of data into the database. The general procedure is:
curr.execute("""INERT INTO Table_Name
(col_name_1, col_name_2, ... )
VALUES (?, ?, ... )""",
(col_1_value, col_2_value, ...) )
Where the tupple of column names (col_name_1, col_name_2, ... ) of the table are followed with a VALUES and then followed by another tupple of '?'. The actual column values for the row are then entered in as a separate tupple (col_1_value, col_2_value, ...).
We do this first for the Person table:
# create dictionary of values
names = ['Bob', 'Sally', 'Wendy', 'Joe']
employee_ids = [1, 2, 3, 4]
salaries = [50, 30, 70, 20]
# loop over all the entries in the dictionary and insert them into the table
for i in range(0,4):
cur.execute("""INSERT INTO Person
(name, id, salary)
VALUES (?, ?, ?)""",
(names[i], employee_ids[i], salaries[i]) )
# commit the changes to disk
conn.commit()
The commit() function forces the executed SQL command to occur on the database on disk. I'll show what happens if you don't do this in a moment, but for now let's do the same thing for the Emails table:
# create dictionary of values
employee_ids = [1, 1, 2, 3, 4]
emails = ['bob@a.com', 'bob@b.com', 'sally@a.com', 'wendy@a.com', 'joe@a.com']
email_ids = [1, 2, 3, 4, 5]
# loop over all the entries in the dictionary and insert them into the table
for i in range(0,5):
cur.execute("""INSERT INTO Emails
(email_id, employee_id, email)
VALUES (?, ?, ?)""",
(email_ids[i], employee_ids[i], emails[i]) )
# commit the changes to disk
conn.commit()
Reading From The Database¶
Reading from the SQLite database is rather straightforward. The following command will return a sqlite.cursor object:
rows = cur.execute("""SELECT * FROM Person""")
print type(rows)
Note: If was a large database we probably dont want to read in all the rows and instead can limit to the first 100 using the command:
SELECT * FROM Person LIMIT 100
The returned sqlite.cursor object will contain all the rows that were returned by the SQL query. We can now loop over all the rows in the table and print them out with the command:
for row in rows:
print row
Notice how the names of the employees are not of tpe str, but are rather unicode! We can also do more advanced queries like this left join:
sql_querry = """SELECT name, salary, email
FROM Person
LEFT JOIN Emails
ON (Person.id = emails.employee_id)"""
joined_rows = cur.execute(sql_querry)
# print the rows in the table
for row in joined_rows:
print row
Updating Values In The Database¶
Updaing the values in a SQLite database is rather straight forward as well. In order to do so, we update a row's column_name1 value by specifying another columns value to identify that row. We'll call this other column to identify the row column_name2. The general comamand is,
UPDATE table_name SET column_name1 = val1 WHERE column_name2 = val2
Let's say Sally gets a raise and now her income changes from 30 to 40, we can do this with the SQLite command,
# Update Sally's salary
cur.execute("""UPDATE Person SET salary = 40 WHERE name = 'Sally' """)
# read in the table and print out the rows
rows = cur.execute("""SELECT * FROM Person""")
for row in rows:
print row
But this only changes the local version of the table and does not persist to the database on disk. We can observe this firsthand if we close the connection to the database, then reconnect again and print out the values:
# close the connection and reopen it.
conn.close()
conn = sqlite3.connect("MyFirstDatabase.db")
cur = conn.cursor()
# read in the table and print out the rows
rows = cur.execute("""SELECT * FROM Person""")
for row in rows:
print row
Now we will commit the update to the database on disk and close the connection. Then we will re-connect to it and print out the data to make sure that it has changed:
# update the row in the table and commit the change to disk
cur.execute("""UPDATE Person SET salary = 40 WHERE name = 'Sally' """)
conn.commit()
conn.close()
# reopen the connection and print the rows in the table
conn = sqlite3.connect("MyFirstDatabase.db")
cur = conn.cursor()
rows = cur.execute("""SELECT * FROM Person""")
for row in rows:
print row
Now we can see that database has been updated!
Deleting Rows From The Database¶
To delete a row from a table in a SQLite database we have to identify the row by one of its column values. The general command is,
DELETE FROM table_name WHERE column_name = val
We can delete Bob from the Person table with the following command:
# delete the row
cur.execute("""DELETE FROM Person WHERE name = 'Bob' """)
# print the rows in the table
rows = cur.execute("""SELECT * FROM Person""")
for row in rows:
print row
Now that we have covered the basic C.R.U.D commands in SQLite let's move on to PostgreSQL!
PostgreSQL¶
While SQLite is fast and easy, it can't handle many concurrent writes. It is also not great for large databases since everything must fit in one file on disk. PostgreSQL is another great option for a relation database that is powerful and open source. PostgreSQL databases are not limited in size and can handle multiple concurrent writes. PostgreSQL manages concurrency through a system known as multiversion concurrency control (MVCC), which gives each transaction a "snapshot" of the database, allowing changes to be made without being visible to other transactions until the changes are committed. This largely eliminates the need for read locks, and ensures the database maintains the ACID (atomicity, consistency, isolation, durability) principles in an efficient manner. The one draw back to PostgreSQL is that is a little harder to set up, which is what I will be focusing on below.
Creating A Database¶
The first thing we will need to do is import the libraries to interact with SQL in Python. These are sqlalchemy and sqlalchemy_utils. We import them in below,
from sqlalchemy import create_engine
from sqlalchemy_utils import database_exists, create_database
dialect+driver://username:password@host:port/databaseAbove we see the general command for how to create a SQL database using Python. The dialect in our case will be postgresql and the driver will be psycopg2. We import the psycopg2 library here,
import psycopg2
Now we define our user name, username, and database name, dbname:
dbname = 'AnotherDatabase'
username = 'Mike'
Then we create the database engine using the above command with the values filled in. Notice below how we do not include the password since we don't want to use one. We also make the host to be localhost since we are going to have the database local on our machine.
engine = create_engine('postgresql+psycopg2://%s@localhost/%s'%(username,dbname))
print engine.url
Now create the database, if it doesn't already exist:
if not database_exists(engine.url):
create_database(engine.url)
print(database_exists(engine.url))
We connect to our database, dbname with the psycopg2 library using the command :
psycopg2.connect(database = dbname, user = username, password = user_password)
where user_password is our password. To connect to our newly created PostgreSQL database we then type,
conn = psycopg2.connect(database = 'AnotherDatabase', user = 'Mike')
We now get our cursor object:
cur = conn.cursor()
And we can create the same Person table as before, except this time instead of name being of type TEXT it is of type VARCHAR.
create_table = """CREATE TABLE IF NOT EXISTS Person
(
name VARCHAR,
id INTEGER PRIMARY KEY,
salary INTEGER
)
"""
cur.execute(create_table)
Inserting the data with PostgresSQL is almost exactly the same as with SQLite except instead of the command using '?' in the tupple after VALUES we use '%s'.
We fill in the values for the Person table below:
names = ['Bob', 'Sally', 'Wendy', 'Joe']
employee_ids = [1, 2, 3, 4]
salaries = [50, 30, 70, 20]
for i in range(0,4):
cur.execute("""INSERT INTO Person
(name, id, salary)
VALUES (%s, %s, %s);""",
(names[i], employee_ids[i], salaries[i]) )
conn.commit()
We repeat the same process for the Email table, except with PostgreSQL we don't have to explicitly state that employee_id is the FOREIGN KEY, but we do still have to say what PRIMARY KEY it references:
# create the table
create_table = """CREATE TABLE IF NOT EXISTS Emails
(
email_id INTEGER PRIMARY KEY,
employee_id INTEGER REFERENCES Person(id),
email VARCHAR
)"""
cur.execute(create_table)
# fill in the table
employee_ids = [1, 1, 2, 3, 4]
email_ids = [1, 2, 3, 4, 5]
emails = ['bob@a.com', 'bob@b.com', 'sally@a.com', 'wendy@a.com', 'joe@a.com']
for i in range(0,5):
cur.execute("""INSERT INTO Emails
(email_id, employee_id, email)
VALUES (%s, %s, %s)""",
(email_ids[i], employee_ids[i], emails[i]) )
conn.commit()
conn.close()
Reading From The Database¶
Now we want to read data in from the table in the database. We first have to connect with the database again and then set the cursor object:
conn = psycopg2.connect(database = dbname, user = username)
cur = conn.cursor()
Now the command to select the rows from the table are exactly the same as with SQLite.
cur.execute("""SELECT * FROM Person""")
However, now the way we view the rows in the table using PostgreSQL is different from SQLite. The command above does not return an object of the rows as it did with sqlite3. Instead, now we get the rows in the table by using one of the following commands on cur:
cur.fetchone()
cur.fetchmany()
cur.fetchall()
For information on these commands see this Stack Overflow post. Since our table is so small we'll fetch all the rows:
cur.fetchall()
We can also do the same left join as before:
sql_querry = """SELECT name, salary, email
FROM Person
LEFT JOIN Emails
ON (Person.id = emails.employee_id)"""
cur.execute(sql_querry)
cur.fetchall()
Updating And Deleting Rows In The Database¶
Updating values and deleting rows in PostgreSQL is exactly the same as in SQLite and don't go into here.
conn.close()
Conclusion¶
I'll be upating this more as time goes on, but for now we can summarize some of the highlights of SQLite and PostgreSQL are:
SQLite¶
SQLite Is probably best for mobile apps or personal projects or where the dataset is not too big and can be stored locally on the machine.
PROS: Requires less configuration than client-server based database. Easy to use, fast, lightweight and has native bindings to Python.
CONS: Cannot handle concurrent writes, instead writes must be performed sequentially. SQLite can handle concurrent reads, but not too many.
PostgreSQL¶
PostgreSQL is the best bet for a large scale open-source databases that will have heavy user traffic.
PROS: Advanced open-source database that scales to large datasets. Can handle multiple concurrent write and reads.
CONS: Can be more complex to set up.