Building & Deploying A Serverless Multimodal ChatBot: Part 1¶
2. Chatting With Llama 3 Using LangChain & Groq
3. Speech & Text With Google Cloud API
4. Putting It Together As An App Using Streamlit
1. Introduction ¶
In this blog post I will go over how to create a create multimodal chatbot using a Large Language Model (LLM). Specifically, I'll build an app that you can speak to and get an audio reply. The app will also optionally transcribe conversation. I will go over how to do this all in a serverless framework and using cloud-based APIs so that (baring the app getting really popular) the costs will be next to nothing!
I'll do this by using LangChain & Groq API to interact with the Llama 3 Open Source LLM and the Google Cloud API for Text-To-Speech and Speech-To-Text. For the front end and deployment I'll use Streamlit, Docker and Google Cloud Run.
Lastly, I wanted to make this app multi-lingual so that my wife could have someone to practice Hebrew with and my mom could practice French with. In this first post I'll cover building the app and running it locally, while in a follow up one I will cover how to deploy the app.
Now let's go over how to use LLMs!
2. Chatting With Llama 3 Using LangChain & Groq ¶
There are many different Large Language Models (LLM) that we can use for this app, but I chose Llama 3 since its Open Source (free); specifically, I used the Llama 3.3 70 Billion parameter model.
For serving the model I used the Groq API since its free for personal use (at least for me so far). There are quite a few methods to interact with Groq and I chose to use LangChain. At first I thought LangChain was a little over engineered (why do you need class for templated prompts? Isn't it just an f-string?), but now I see the point and am on-board! LangChain allows for a consistent API across most models and abstracts away a lot of pain points. The prompt templates do make sense now, and my only complaint is I cant tell what library something should come from (langchain, langchain_core, langchain_community?), but given how much the API has changed around, it seems neither does the community. :-)
I'll start off going over how to use an LLM first. First thing I'll do is import ChatGroq class and use pydot-env to load environment variables that have my API keys.
from langchain_groq import ChatGroq
from dotenv import load_dotenv
load_dotenv()
True
Instantiating the ChatGroq chat object gives me a model that I can query using the invoke method:
llm = ChatGroq(
model="llama-3.3-70b-versatile",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2)
result = llm.invoke("What is the square root of 9?")
The returned object is of type AIMessage and the message can be obtained with the .content attribute:
print(result.content)
The square root of 9 is 3.
Simple enough!
We can go one step further and use the StrOutputParser to get the result as just a string.
from langchain_core.output_parsers import StrOutputParser
parser = StrOutputParser()
print(parser.invoke(result))
The square root of 9 is 3.
We can put them together and create a simple chain using the | operator:
chain = llm | parser
print(chain.invoke("What is the square root of 9?"))
The square root of 9 is 3.
Now let's go over using a PrompteTemplate in LangChain. PromptTemplates are used to create prompts (questions/queries) that can have variables in them (like f-strings). This allows user to chain together the prompt with the LLM into a pipeline that is called a "chain." Then the user only has to invoke the chain with an input dictionary that has the variables and their values and they will get back out the response for that user prompt!
Let's show how TemplatePrompts work and how to use them with LLMs as a chain. First we import the PromptTemplate class and create a template string that looks sort of like like an f-string
from langchain_core.prompts import PromptTemplate
template = "What is the square root of {n}?"
Now we use the from_template class method (I have not seen it them used that often!) to make a templated prompt:
prompt = PromptTemplate.from_template(template)
prompt
PromptTemplate(input_variables=['n'], input_types={}, partial_variables={}, template='What is the square root of {n}?')
Now the actual prompt can be created by filling in the variable n using a dictionary from the invoke method,
prompt.invoke({"n": 9})
StringPromptValue(text='What is the square root of 9?')
Now the really cool thing is when we chain the PromptTemplate and the LLM together into a "chain" using the | operator to represent seperate components of the chain:
chain = prompt | llm | parser
This allows the user to input a value of n=16 using dictionary with a single invoke command and get back the reply!
result = chain.invoke({"n": 16})
print(result)
The square root of 16 is 4.
Great!
Now we can put it all together to create a function that takes a message in one language and converts it into another. I'll need this if the my end user speaks one lanuages and wants the bot to reply in another.
def translate_text(language: str, text: str) -> str:
if language not in ("English", "French", "Hebrew"):
raise ValueError(f"Not valid language choice: {language}")
template = "Translate the following into {language} and only return the translated text: {text}"
prompt = PromptTemplate.from_template(template)
llm = ChatGroq(
model="llama-3.3-70b-versatile",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2)
translation_chain = prompt | llm | StrOutputParser()
result = translation_chain.invoke(
{
"language": language,
"text": text,
}
)
return result
Notice I use the prompt to not only to pass in the users question, but also to tell the LLM to reply back in a specified language. Let's try it out!
result = translate_text(language="French", text="Hello World!")
print(result)
Bonjour le monde !
One issue with just using the LLM for chat bots is that it wont remember anything we asked previously! See the example below:
print(llm.invoke("Set x = 9").content)
print(llm.invoke("What is x + 3?").content)
x = 9 To determine the value of x + 3, I would need to know the value of x. Could you please provide the value of x?
The LLM has no recollection of anything from prior invocations!
We have add a "memory" our AI chatbot. At first I thought memory was something special, but its really keeping a record of the conversation and feeding the entire convesation so fare into the LLM before asking another question. The chat history will look like list of tuples. The first entry to the tuple signifies whether it is the "ai" system (chatbot) or the "human" and the second entry in the tuple is the actual message. For example the conversation above could be seen as,
history = [
("human", "Set x = 9"),
("ai", "9"),
("human", "What is x + 3?"),
...
]Similar to the PrompteTemplate there is a ChatPromptTemplate that can be used to create the history of the chat conversation. This used in conjunction with the MessagePlaceholder to unwind the conversation into a prompt with the entire history and the new question at the very end.
An example is below:
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder("history"),
("human", "{question}")
]
)
history = [("human", "Set x = 9"), ("ai", "9")]
prompt.invoke(
{
"history": history,
"question": "What is x + 3?"
}
).messages
[HumanMessage(content='Set x = 9', additional_kwargs={}, response_metadata={}),
AIMessage(content='9', additional_kwargs={}, response_metadata={}),
HumanMessage(content='What is x + 3?', additional_kwargs={}, response_metadata={})]
Now we can form a chain with memory:
history = []
chain = prompt | llm | parser
question = "set x = 9"
answer = chain.invoke({"history": history, "question": question})
history.extend([("human", question), ("ai", answer)])
question = "what is x + 3?"
print(chain.invoke({"history": history, "question": question}))
x = 9 x + 3 = 12
Putting it all together into a function below using the history concept from above,
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from typing import Iterator, List, Tuple
def ask_question(
llm: ChatGroq,
history: List[Tuple[str, str]],
question: str,
ai_language: str,
) -> str:
prompt = ChatPromptTemplate.from_messages(
[
("system", f"""You are a helpful teacher having a conversation with a student in {ai_language}.
Only reply back in {ai_language} not matter what language the student uses."""),
MessagesPlaceholder("history"),
("human", "{question}")
]
)
chain = prompt | llm | StrOutputParser()
answer = chain.invoke(
{
"history": history,
"question": question
}
)
return answer
print(
ask_question(
llm=llm,
history=history,
ai_language="English",
question="What is x + 3?"
))
To find the value of x + 3, we need to add 3 to the value of x. Since x = 9, we get: x + 3 = 9 + 3 = 12 So, x + 3 is equal to 12.
Now the prompt I set in prepending the history allows me to get the answer in any language! For instance,
answer = ask_question(
llm=llm,
history=history,
ai_language="French",
question="What is x + 3?")
print(answer)
Pour trouver la valeur de x + 3, il faut ajouter 3 à la valeur de x. Puisque x = 9, on a x + 3 = 9 + 3 = 12. La réponse est donc 12.
Now in English! (The math in Hebrew got messed up with sentences being read right to left... )
print(translate_text(language="English", text=answer))
To find the value of x + 3, you need to add 3 to the value of x. Since x = 9, we have x + 3 = 9 + 3 = 12. The answer is therefore 12.
Very cool!!
LangChain makes this so easy!
We now have enough to make a ChatBot, but I wanted to take this one step further and have an application you can speak with in one language and it would speak back to you in another (or the same) language.
3. Speech & Text With Google Cloud API ¶
In order to make an app that an end user can chat with using speech, we need to use Speech-To-Text to convert the end users audio into text that can be feed into the ask_question function above.
The resulting response from the LLM can be converted into an audio reply using Text-To-Speech and played back to the end users. There are actually pretty straight forward using the Google Cloud API. I will just reference the code I wrote, speech_to_text and text_to_speech and note that there are plently of languages that Google supports!
The one tricky part is setting up the API keys to be able to use these capabilities. The first step is to enable the Speech-To-Text and the Text-To-Speech services on your account. Next you will need to create an API key that you can use to access them. You can go to your console then select "APIs & Services" -> "Enabled APIs & services" as shown below:
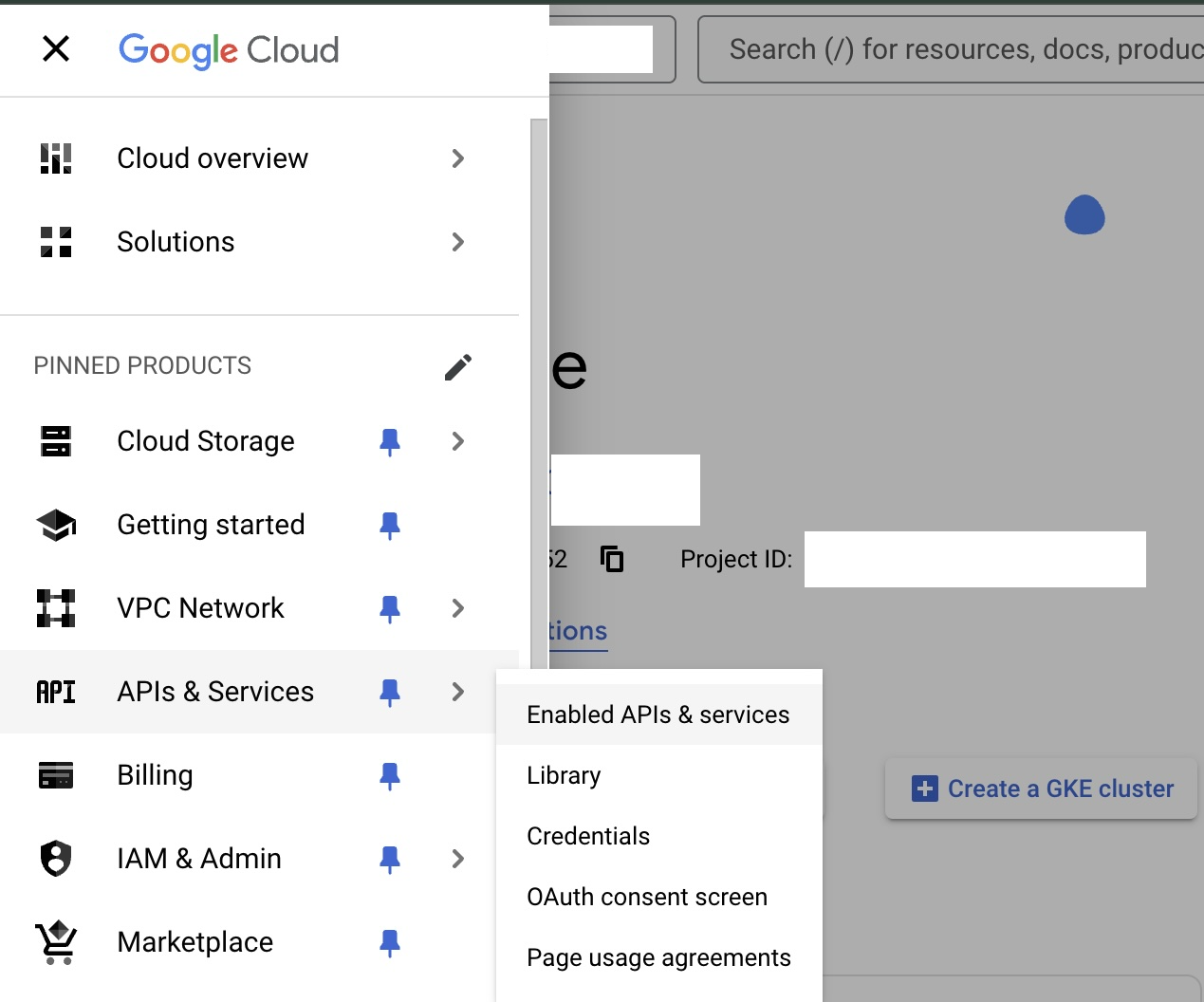
Then on the left sidebar select the "Credentials" tab, then on the top click "Create Credentials" and select "API key" from the drop down,
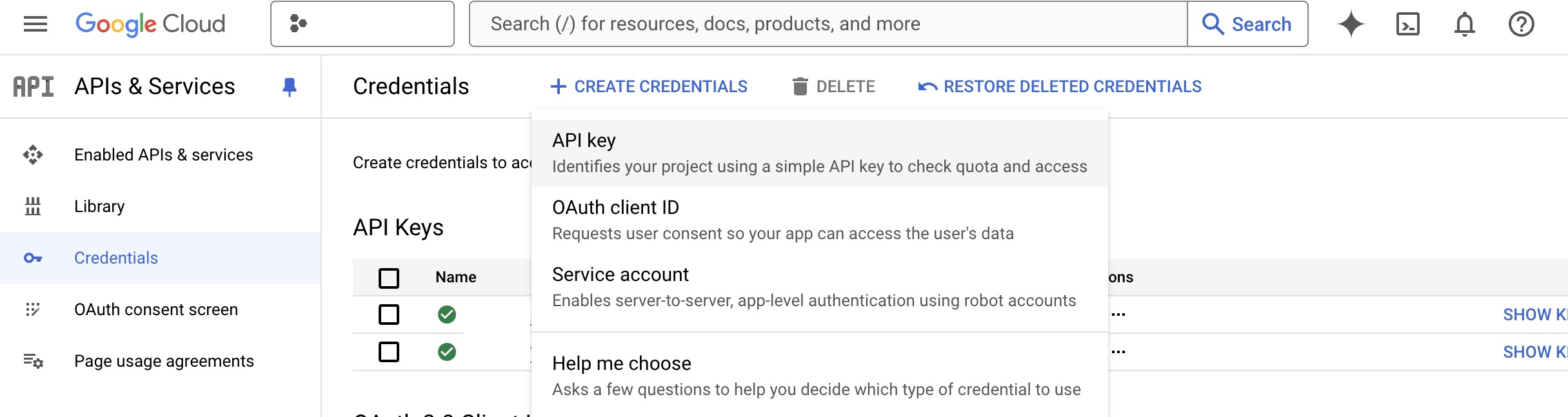
Once you create your API key it will have unlimited access by default, so let's restrict the access. You can click edit the API Key, and then under the "API Restrictions" section click "Restrict Key" and search for the "Text-To-Speech" and "Speech-To-Test" services,
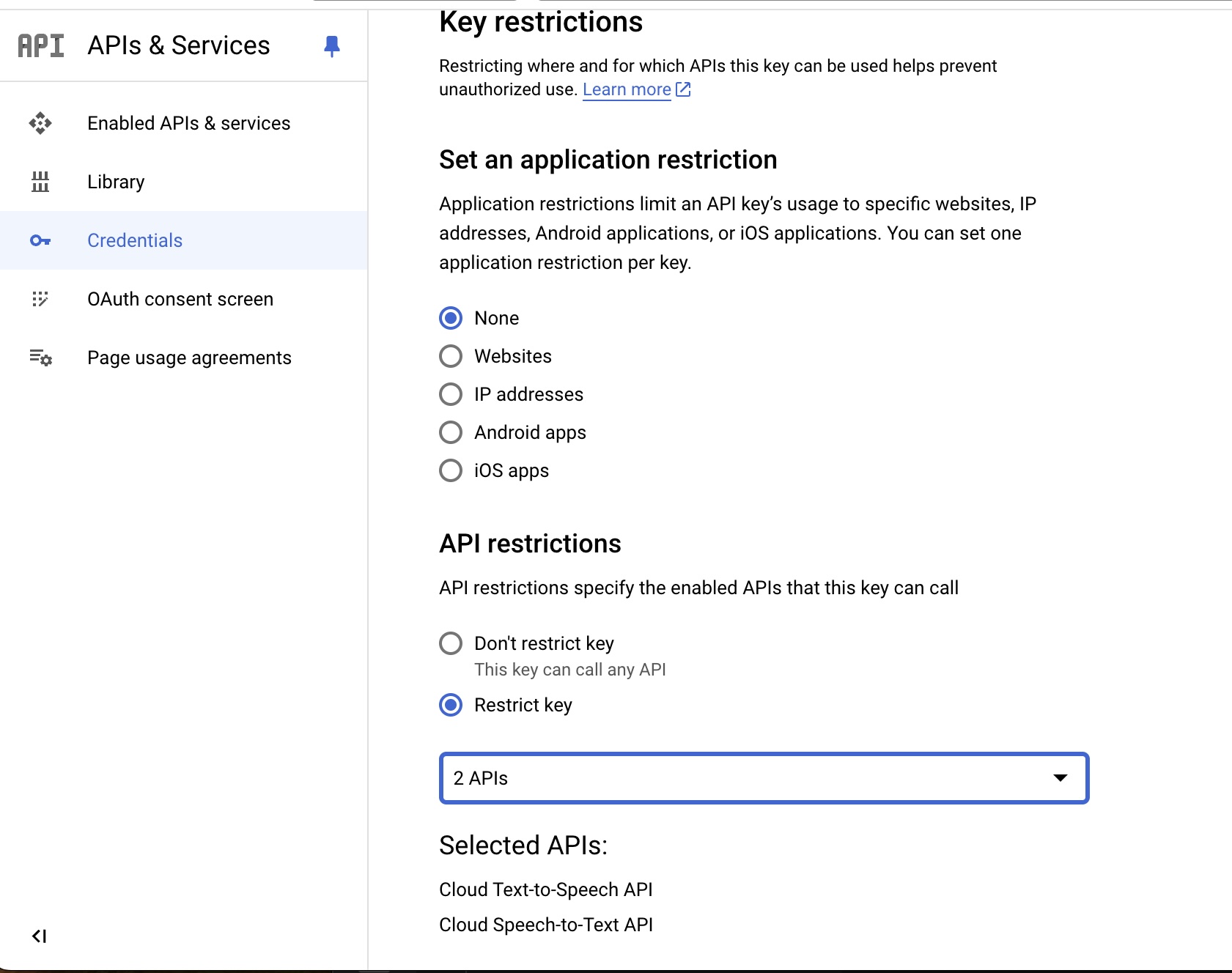
If you can't find the services in the search that probably means you didn't enable them in your account.
4. Putting It Together As An App Using Streamlit ¶
Now in order to make an app that people can interact with we need to create a front end. In the past I have done this more or less by hand using Flask and FastAPI. Nowdays many people use Streamlit to create apps which is MUCH easier!
My Streamlit app is written module main.py and uses the audio_input function to capture the end users questions and uses the speech_to_text function to convert the audio to text. Before the question is sent to the ask_question function above I use the following function to convert the history of chats into list of tuples as shown above,
def tuplify(history: List[Dict[str, str]]) -> List[Tuple[str, str]]:
return [(d['role'], d['content']) for d in history]
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[33], line 1 ----> 1 def tuplify(history: List[Dict[str, str]]) -> List[Tuple[str, str]]: 2 return [(d['role'], d['content']) for d in history] NameError: name 'Dict' is not defined
The LLM'S response is converted back to audio using the text_to_speech function and uses Streamlit's audio function to play the response.
As I mentioned, in order to make LLM have memory I need to keep track of the conversation. I do so by using a list called messages. The way Streamlit works is that it runs the entire script from top to bottom any time anything in changed, so the messages would be cleared after the first run. In order to to maintain a history of the conversation I had to save them part of the session_state. The last tricky part that I had to figure out was how to create a button to clear the messages. Every time I tried, it still had the variable from the audio_input set and I couldnt clear the first message. In order to fix this I had to create a form along with using the form_submit_button and viola the clear button now worked!
You can try running the app using the command,
streamlit run src/main.py If your browser doesn't automatically open, you can go to https://localhost:8051 and you will be able to see something similar to the below,
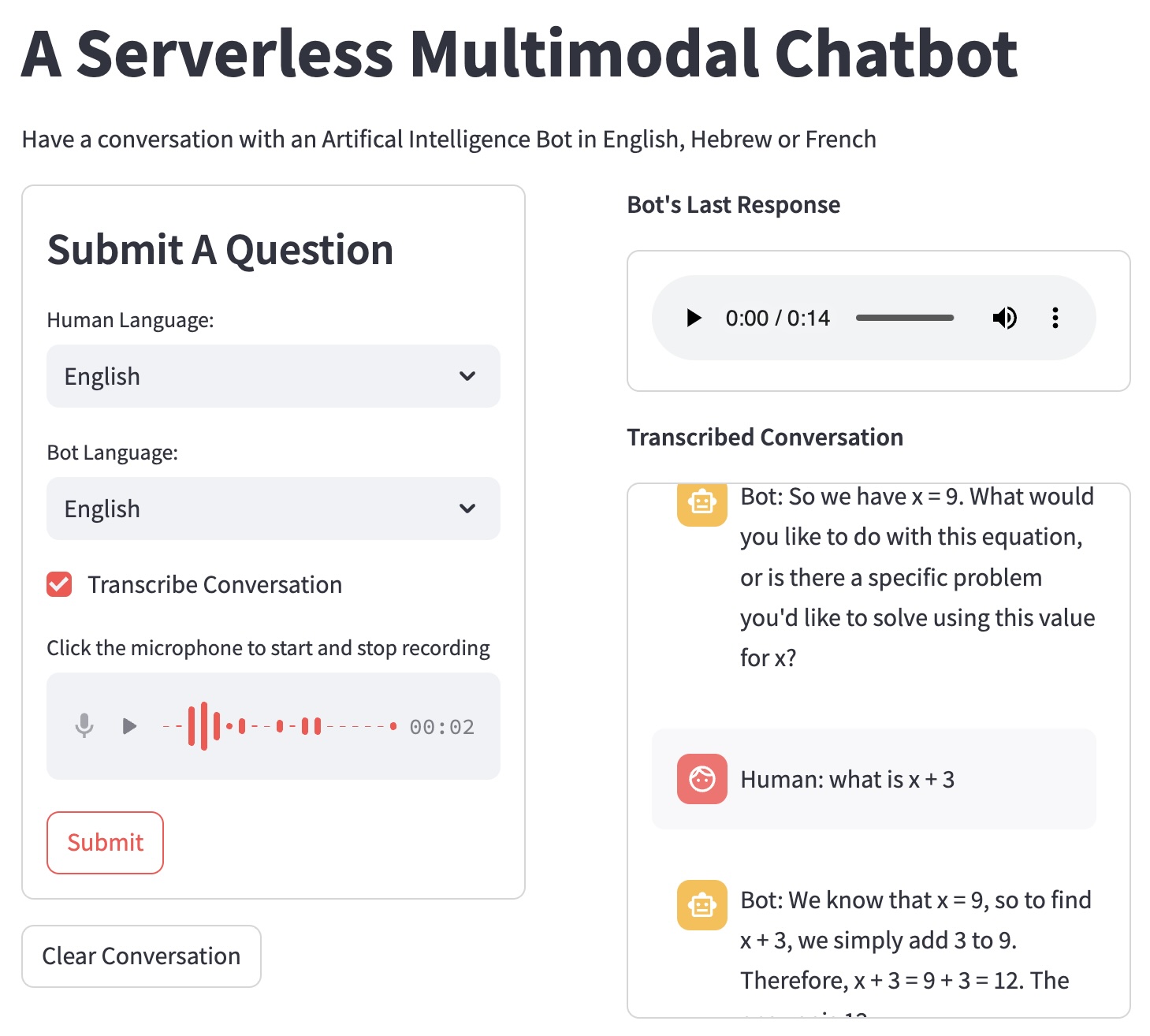
5. Next Steps ¶
In the next post I'll cover how to deploy this app using Docker for containerization which will allow us to run the app both locally and on the cloud. Then well cover GitHub Actions for automatically building the image and pushing it to Docker Hub where it can be pulled and run on Google Cloud Run to create a serverless application.