Creating An AI-Based JFK Speech Writer: Part 1¶
Introduction¶
One of the most quintessential projects to complete when getting started with Deep Learning and Natural Language Processing is using text generation with Recurrent Neural Networks. The internet is littered with examples of people training a neural network on works of Shakespeare and using the network to generate new text that mimics Shakespeare's style. I wanted to do something along these lines, but a little more creative. Many would agree one of the best orators of all time would have to be John F. Kennedy. I am a personally a big nerd of an President Kennedy's speeches and spent many hours listening to his words. So I started this project to see if could write a neural network to generate a Kennedy-like writings.
Speeches written by the President, Senators & Representatives (JFK was all 3) are under the public domain which means they are publicly available! In this first part, I will quickly go over how I was able to create a training set of JFK's speeches.
Web Scraping JFK Speeches With BeautifulSoup¶
The first place I went to get President Kennedy's speeches was his Presidential Library's Website. The website has a list of each speech at the address, https://www.jfklibrary.org/archives/other-resources/john-f-kennedy-speeches. The site has quite a few pages with link for each speech as well as the date it occurred as shown below,
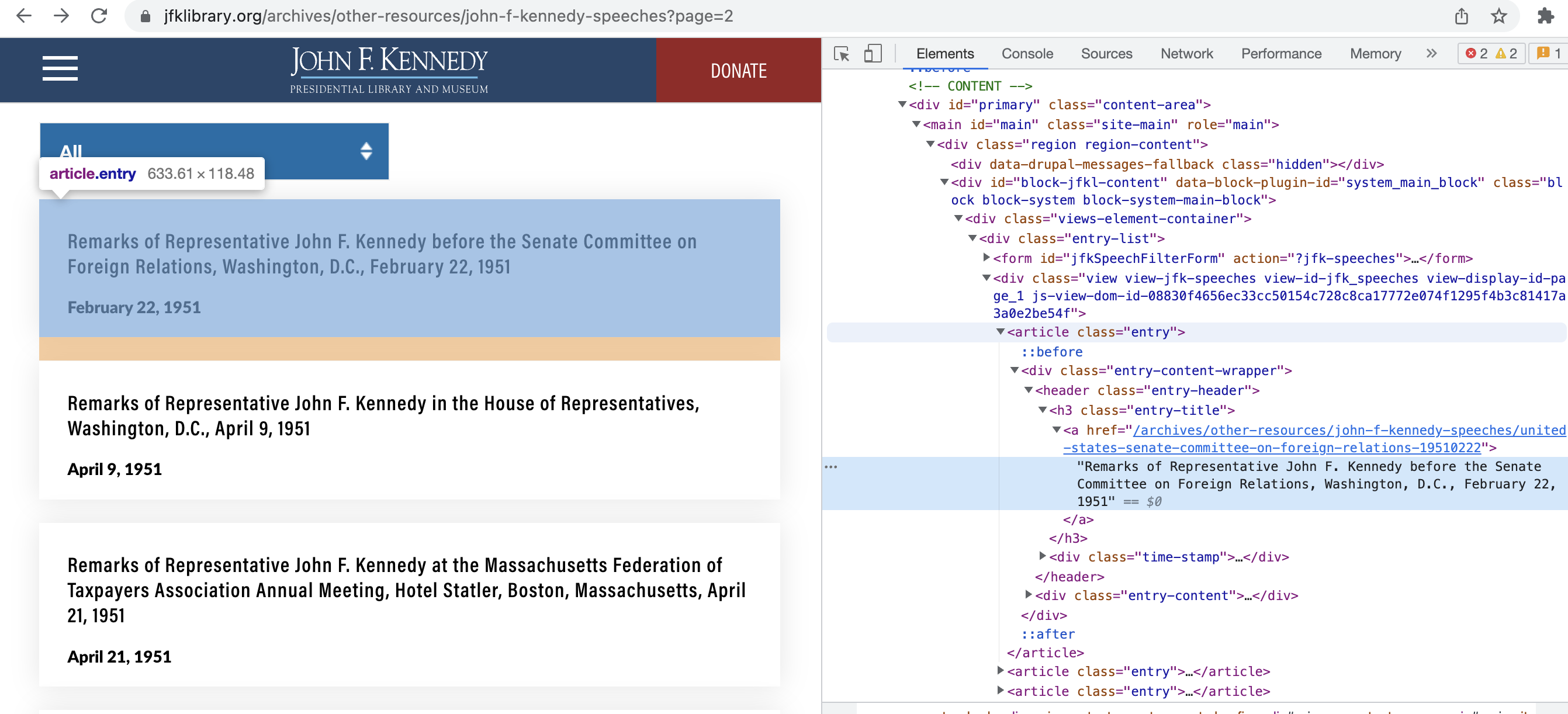
Each page is indexed in the web address by the ?page=N, so I can loop through all the pages by loop from 1 to N. I found where in the HTML that corresponds to each link by using the Inspect Tool in Google Chrome. Each speech is labeled by the tag article in HTML with the link for the speech being given after the href tag.
Once I figured this out, I could use the requests package along with BeautifulSoup to scrape the links from the HTML. I created a simple function to loop over all the pages and create an array of links to Kennedy Speeches from the library's website as shown below.
import requests
from bs4 import BeautifulSoup
def get_soup(address: str, num: int = None) -> str:
if num is not None:
page = requests.get(f"{address}?page={num}")
else:
page = requests.get(f"{address}")
soup = BeautifulSoup(page.text, 'html.parser')
return soup
def get_links():
address = "https://www.jfklibrary.org/archives/other-resources/john-f-kennedy-speeches"
page_nbs = range(1,18)
links = []
for num in page_nbs:
soup = get_soup(address, num)
links.extend([article.find("a")["href"] for article in soup.find_all("article")])
return links
I can then use this function to get all links:
links = get_links()
We can see the first link,
link = links[0]
print(link)
We can get the entire web address with the prefix shown below:
print(f"https://www.jfklibrary.org/{link}")
Next we create a bucket to write all the speeches to Google Cloud Storage using the package goolge-cloud-storage. The documentation for API can be found here. First well create a client to connect to our Google Cloud project:
from google.oauth2 import service_account
from google.cloud import storage
from google.cloud.exceptions import Conflict
credentials = service_account.Credentials.from_service_account_file('credentials.json')
client = storage.Client(project=credentials.project_id,
credentials=credentials)
Then we'll create a bucket called harmon-kennedy and if it already exists then we'll connect to it:
try:
bucket = client.create_bucket("harmon-kennedy")
except Conflict:
bucket = client.get_bucket("harmon-kennedy")
bucket
We'll save each speech as text file with the name coming from the text after the last backslash in the link. This can be accomplished with the function below,
def get_name(link: str) -> str:
name = link.partition("/john-f-kennedy-speeches/")[2]
return f"{name}.txt"
For example the link above we'll get the name of the file using the function:
get_name(link)
Looking at one of the pages from the links to the speeches below, we can see that the bulk of the speech is referenced by the article tag:
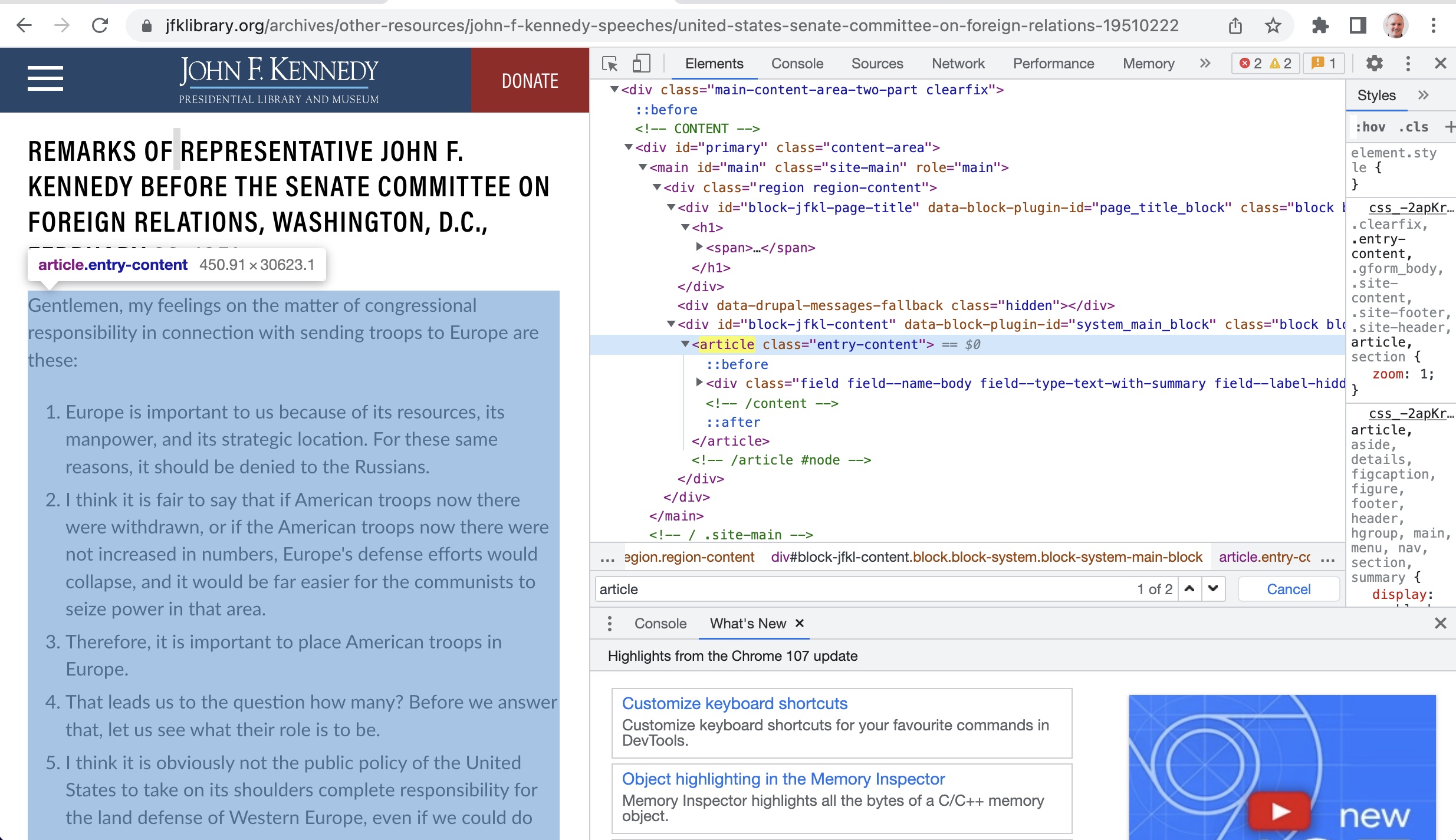
We can use this fact to scrape the speech from the page by finding the article tag and then taking the associated text from it. In BeautifulSoup the syntax to do this is,
soup.find("article").text
Next we can write a function that creates file in the bucket called file_name and writes the text of the associated speech into that file as a string:
def upload_speech(file_name: str, speech: str) -> None:
blob = bucket.blob(file_name)
blob.upload_from_string(data=speech, content_type='text/plain')
Lastly, we write one last function that will take in each link, scrape the speech from the site associated with the link and then upload the speech as a text file to the bucket:
def speech_to_bucket(link: str) -> None:
address = f"https://www.jfklibrary.org/{link}"
soup = get_soup(address)
filename = get_name(link)
speech = soup.find("article").text
upload_speech(filename, speech)
Now we'll loop over each link in links and upload the speech to the bucket:
for link in links:
speech_to_bucket(link)
Next Steps¶
In this short post we went over how to scrape the JFK library's website to create a collection of JFK speeches. We covered how to do this using BeautifulSoup and upload them as text files to Google Cloud Storage. One thing I could do to improve upon this is to use an asynchronous HTTP client AIOHTTP to read and write using asynchronous I/O and improve runtime.
In the next post we'll go over how to build a speech writer using Recurrent Neural Networks. Hope you enjoyed this!