GreenBuildings3: Build & Deploy Models With MLflow & Docker¶
Contents¶
3. Linear Regression & Logging A Simple Run
4. XGBoost & Logging Nested Runs for GridSearchCV
5. MLflow Models: Model Serving With REST APIs
6. Deploying to Google App Engine with Docker
Introduction ¶
This is the third and final post in a series of blog posts about energy usage and green house gas emissions of buildings in New York City. In the first post I covered exploratory data analysis and outlier removal. In the second post I covered imputing missing values. These topics make up the majority of what is called "data cleaning". This last post will deal with model building and model deployment. Specifically I will build a model of New York City building green house gas emissions based on the building energy usage metrics. After I build a sufficiently accurate model I will convert the model to REST API for serving and then deploy the REST API to the cloud.
The processes of model development and deployment are made a lot easier with MLflow library. Specifically, I will cover using the MLflow Tracking framework to log all the diffent models I developed as well as their performance. MLflow tracking acts a great way to memorialize and document the model development process. I will then use MLflow Models to convert the top model into a REST API for model serving. I will go over two ways MLflow Models creates REST API including the newly added method that uses Docker. Finally I will show how to simply deploy the "Dockerized" API to the cloud through Google App Engine.
Note the MLflow library is still relatively new and the APi may change, for this purpose I should remark that I am working with MLflow version 1.8.0. I should also point out that model serving through Docker was experimental in MLflow 1.8.0 and may have changed since I finished this project.
Working With MLflow ¶
MLflow is an open source tool to make machine learning easier and more reproducible and was create by Databricks (the same people who created Apache Spark). There are many components to MLflow, but the two I will be looking at are,
- MLflow Tracking : A tool for logging modeling experiments
- MLflow Models : A tool for serving models as REST APIs
I will stick to using MLflow locally instead of a production set up. You can start the Web UI with the command:
mlflow ui --host=0.0.0.0 --port=5050
Then going to the website http://0.0.0.0:5050 in your web broswer where we will see the following:
We can see the generic MLflow website without any modeling experiment data. This will change soon enough. We can collect modeling information into "experiments" that will contain "runs". Each run could be one model or a series of different models each trained with different parameter values. In this way MLflow tracking is great for organizing and maintaining as much information about the development process as you like.
Locally, MLflow will create a file directory called,
mlruns
that will be housed in the same path that the mlflow ui was run in. Let's import the library along with some other basic libraries:
import mlflow
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set()
We can see what the MLflow tracking url is to see where all the data for MLflow will be stored (i.e. where mlruns directory is):
mlflow.get_tracking_uri()
Now let's create an experiment for this project and get started!
try:
mlflow.create_experiment("greenbuildings")
experiment = mlflow.get_experiment_by_name("greenbuildings")
except:
experiment = mlflow.get_experiment_by_name("greenbuildings")
We can see that we get an "experiment" that has a number of attributes:
print(experiment)
These attributes include:
- artifact_location (where the metadata + models will be stored)
- experiment_id (id to help us track the experiment)
- lifestyle_stage (whether its active, deleted, etc.)
- name (experiment name)
- tag
The experiment_id is an important attribute and will be used quite frequently to know where to log and organize all the modeling information. Let's set that number as a variable to use later:
exp_id = experiment.experiment_id
Let's move on to building our first model for predicting green house gas emission of buildings.
Linear Regression & Logging A Simple Run ¶
Let's build a predictive model for green house gas emissions by multifamily homes and offices in New York City. We'll do this at first using a simple linear regression model. While not the best in terms of predictive performance it is often a great first step since it allows us to interpet the effect each feature has on the predicted green house gas emissions. We'll discuss this more later, but for now lets import our data from Google BigQuery using the set up from the previous posts:
from google.oauth2 import service_account
from google.cloud import bigquery
import json
import pandas_gbq
credentials = service_account.Credentials\
.from_service_account_file('./derby.json')
pandas_gbq.context.credentials = credentials
pandas_gbq.context.project = credentials.project_id
df = pandas_gbq.read_gbq("""
SELECT
CAST(Energy_Star AS INT64) AS Energy_Star,
Site_EUI,
NGI,
EI,
GHGI,
CAST(Residential AS INT64) AS Residential,
FROM
db_gb.clean_data
""")
And get the target variable and features:
X = df.drop("GHGI",axis=1)
Y = df["GHGI"]
Let's remind ourselves what the distribution of the target variable and predictors look like using the pairplot shown in the last post:
sns.pairplot(df,
vars=["Energy_Star","Site_EUI","NGI","EI","GHGI"],
size=2,
hue='Residential')

We can from the last row in this graph that the relationship between GHGI and Site_EUI, NGI, as well as EI is somewhat linear, but the relationship of GHGI and Energy_Star is less well defined.
Let's create our train and test set as well fix our random state (to have repeatable datasets)
from sklearn.model_selection import train_test_split
random_state = 93
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=random_state)
As we stated earlier we'll start out with a Linear Regression model since it is simple and interpertable. We can easily implement a least squares regression model using Scikit-learn:
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score, mean_squared_error
pipe = Pipeline([('scaler',StandardScaler()),
('reg', LinearRegression())])
model = pipe.fit(X_train, y_train)
We can then evaluate the model performance ($R^{2}$-score) on the test set to see how much variance in the model we are able to explain as well as the mean square error (MSE):
y_pred = model.predict(X_test)
print("R2 score: {}".format(r2_score(y_test, y_pred)))
print("MSE: {}".format(mean_squared_error(y_test, y_pred)))
We can explain 64.76% of the variance which is pretty good, but definitely leaves room for improvement. Let's take a look at the coefficients of the linear regression model.
# get the last stage of the pipeline which is the model
reg = pipe.steps[1][1]
# print the coefficients
for coef in zip(X_train.columns, reg.coef_):
print(coef)
The model coefficents can be interpreated as folllows: for continuous feautres, an increase in one of their in units yields an increase in the unit of green house emissions that is equal to the coefficent. For example, increasing Site_EUI by 1 unit increase GHGI by 0.00164 units. We can see that increasing the electricty, energy intensity, and natural gas intensity increases green house gas emissions which makes sense. Increasing the Energy Star rating of the building tends to decrease the greenhouse gas emissions which makes sense. It also seems that residential buildings tend to emit more green house gases than office space buildings, albiet weakly.
We can measure the p-values for coefficents by using Scikit-Learns's f_regression function.
from sklearn.feature_selection import f_regression
f_stats, pvals = f_regression(X_train, y_train)
for coef in zip(X_train.columns, pvals):
print("{0}'s p-value : {1}".format(coef[0],coef[1]))
We see that even though the coeficients of the regression model are rather small, their small p-values show that they are still signifcant and should be included in our model. Overfitting a linear model can be quite obvious from the coefficients when one of the features has a large absolute value. In our model this does not seem to be the case and we don't have to consider overfitting or using regularization further.
Let's add a run to the MLflow experiment that corresponds to this model. We use the start_run function and pass the experiment id along with the name for this run being "Linear Regression"
run = mlflow.start_run(experiment_id=exp_id, run_name="Linear Regression")
We can see that we have an active run that is a RunInfo entity that maintains information about the run:
run.info
We can add the metrics for our model using the add_metrics functions:
mlflow.log_metric("r2" ,r2_score(y_test, y_pred))
mlflow.log_metric("mse", mean_squared_error(y_test, y_pred))
Let's look at some of the residuals in the continuous features to see if we can find any non-linear patterns that might signal ways improve the model.
from Plotting_Functions import plot_residuals
f = plot_residuals(X_test = X_test,
y_test = y_test,
y_pred = y_pred)

There are no obvious patterns in the residuals, but at the same time they do not appear to be normally distributed as the theory says they should be. This tells me that we might be able to use a more flexible model to capture the nonlinearities in the relationships.
We can log this image as well using the log_artifact method:
f.savefig("resid.png")
mlflow.log_artifact("resid.png")
For the time being let's log the model using the so called scikit-learn flavor and end the run:
import mlflow.sklearn
mlflow.sklearn.log_model(model, "LinearModel")
mlflow.end_run()
We can go to the MLflow UI to see that the run has been added with its metrics:
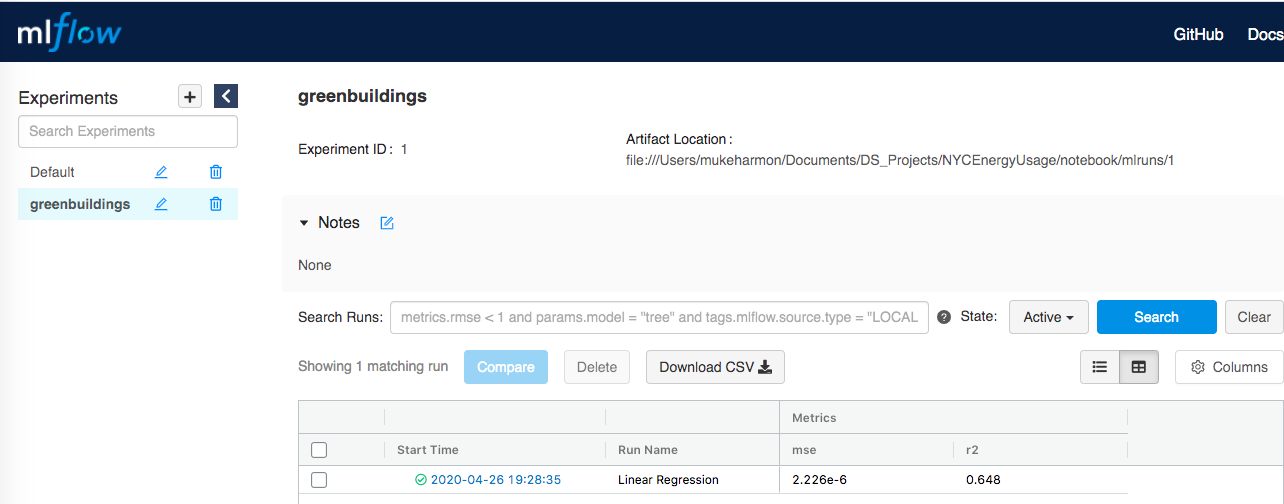
Clicking on the run we can see the model performance metrics, logged model and artifacts:
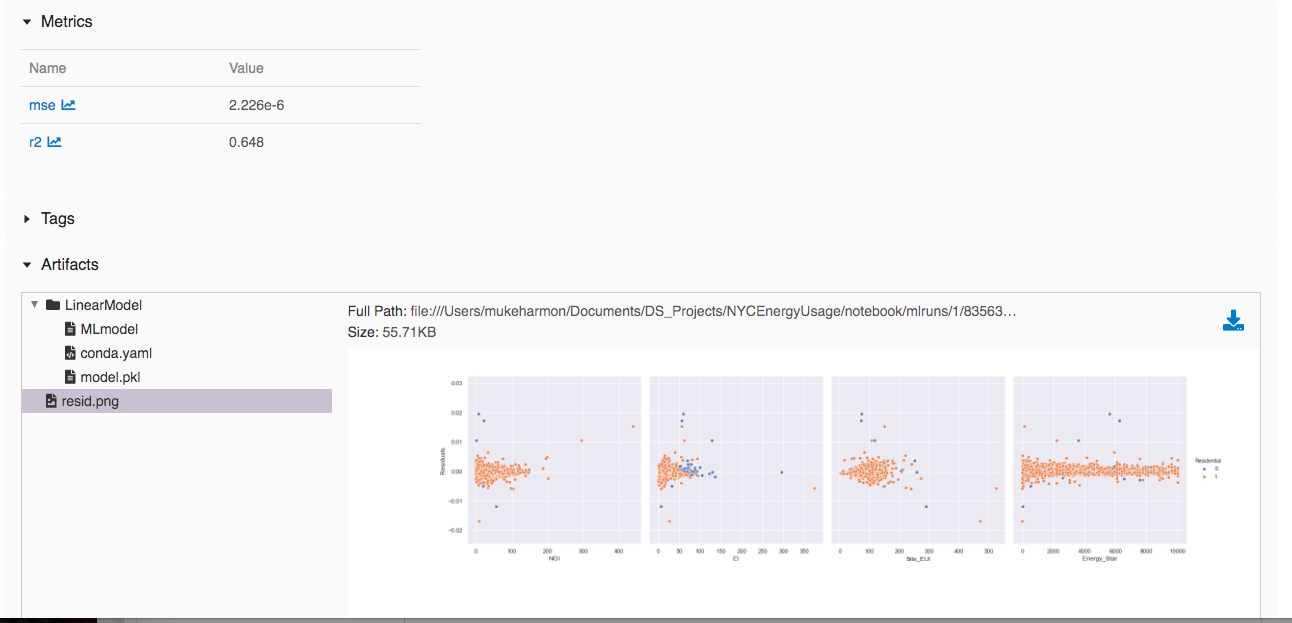
The LinearModel folder under the artifacts tab contains the conda environment (conda.yml), the pickled model (model.pkl) and associated metadata (MLModel). We should note that the conda.yml file is used to package all the necessary libraries for serving the model model.pkl.
XGBoost & Logging Nested Runs for GridSearchCV ¶
Let's try another model to see if we cant improve the $R^2$ score and MSE. One algorithm that performs quite well is XGBoost. XGBoost is a based on gradient boosted decision trees and is one of the best performing machine learning models avaiable. It builds the model in a stage-wise fashion like other boosting methods do, and it generalizes them by allowing optimization of an arbitrary differentiable loss function. You can read more about gradient boosting here.
Let's import the XGBoost Regressor and then run a small grid search using cross-valiation to find the optimal parameter values:
from xgboost import XGBRegressor
from sklearn.model_selection import GridSearchCV
# define the parameter values
paramters = {"n_estimators" :[10,15,25,50,100,150],
"max_depth" :[3,5,7,10],
"loss" :["ls", "lad"]
}
# define the grid search and optimization metric
grid = GridSearchCV(estimator=XGBRegressor(),
param_grid=paramters,
scoring="r2",
cv=5,
n_jobs=-1)
# perform the grid search
xgb_model = grid.fit(X_train, y_train)
NOTE: Scaling is unnecessary for tree based methods.
Now that we have the best model from our grid search over the trainin set let see how it performs on the test set:
y_pred = xgb_model.predict(X_test)
print("R^2 score: {}".format(r2_score(y_test, y_pred)))
print("MSE {}".format(mean_squared_error(y_test, y_pred)))
A definite improvement in the $R^2$ score and MSE! Let's take a look at the residuals:
f = plot_residuals(X_test = X_test,
y_test = y_test,
y_pred = y_pred)
f.savefig("resid.png")

Not terribly different than the linear regression model, but we see less outliers in the relationship between NGI and the residuals.
While we have improved our prediction capabilities, one draw back to more complex models like XGBoost is that they are less interperable. Despite this draw back, XGBoost still allows to the find the relative importance of the features:
model = grid.best_estimator_
for coef in zip(X_train.columns, model.feature_importances_):
print(coef)
While we know the importance of the features we don't now how they effect the GHGI, i.e. if the NGI does the GHGI go up or down? By how much does it go up or down? Given what we see just from the above these are not questions the model can answer in general terms. This is what we mean by model interperability!
Now let's log all the information from the grid search and each of the models performances using a nested run using a "with" statement:
with mlflow.start_run(
experiment_id=exp_id,
run_name="XGBoostRegressor",
nested=True
):
# Get the grid cell results
cv_results = grid.cv_results_
# loop over each of the parameters and log them along
# with the metric and rank of the model
for params, metric, rank in zip(cv_results['params'],
cv_results['mean_test_score'],
cv_results["rank_test_score"]):
with mlflow.start_run(experiment_id=exp_id,
nested=True):
# log the parameters
mlflow.log_params(params)
# log the R2 score
mlflow.log_metric("r2",metric)
# set the rank
mlflow.set_tag("rank",rank)
# For the best estimator (xbg_model)
# let's log the parameters for the best model and
# its metric artifacts
mlflow.log_params(grid.best_params_)
mlflow.log_metrics({"r2" : r2_score(y_test, y_pred),
" mse": mean_squared_error(y_test, y_pred)})
mlflow.log_artifact("resid.png")
mlflow.log_model("XGBoost",xbg_model)
Let's take a look at the MLflow UI again:
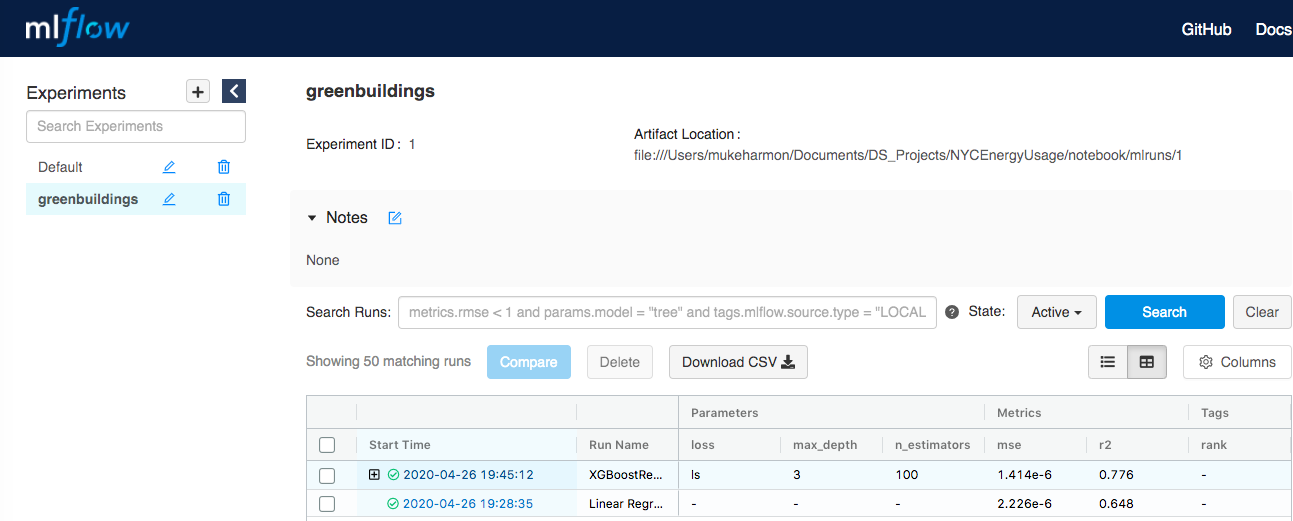
We can see the + symbol on the left side of the Run Name corresponding to the run "XGBoostRegresor". Clicking on the symbol shows the rest of the results from the grid search as a dropdown:
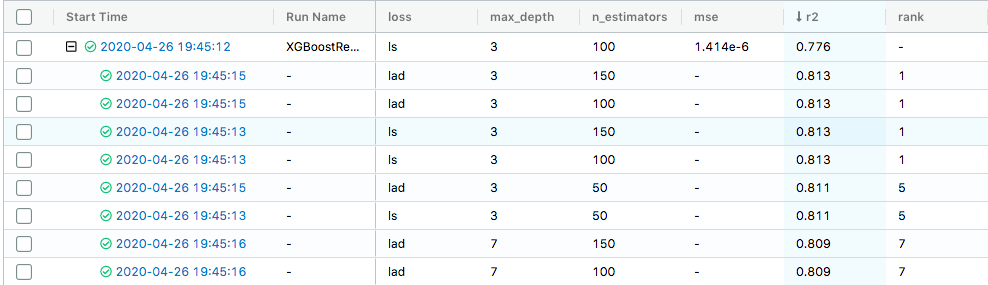
We can see the different parameters used in each of the runs, the $R^2$ value for that model as well as the ranking of that model. Notice that the first model and the last of the models with rank 1 are the same. However, their $R^2$ values are different. This is because the one is the model perfomance on the test set, while the other is the average model of the model performances in the 5-fold cross validation.
Another nice feature of MLflow is the ability to compare model runs, to see the effect of say a hyper-parameter on model performance. You can select the model runs from the drop down and click the "compare" button displayed in the pictures above. I took a sample from the grid search above to see the effect of max_depth on the model with 100 estimators and ls for its log function:
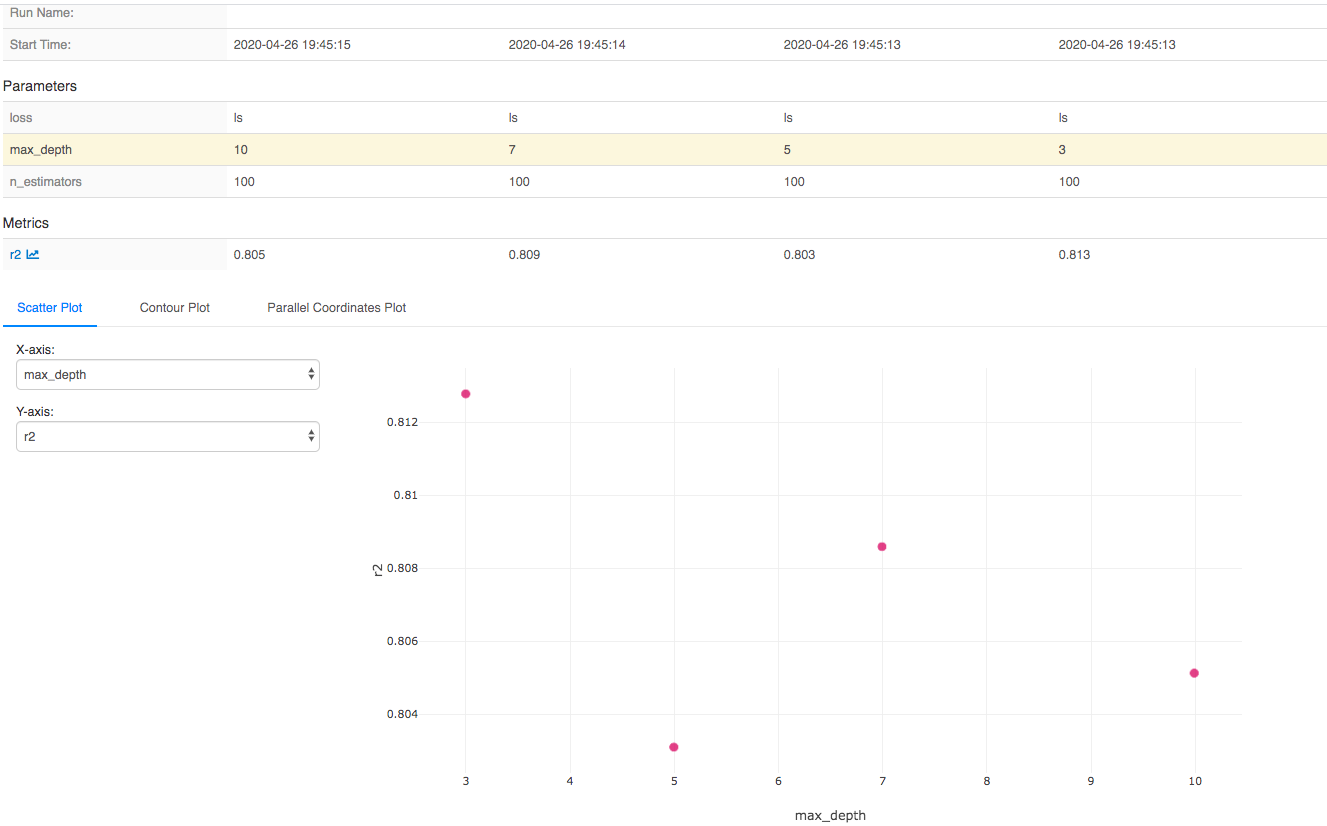
We can see that the $R^{2}$ decreases as the max_depth increases. This makes sense as taking larger values of the max_depth generally leads to overfitting.
MLflow Models: Serving With REST APIs & Docker¶
Now that we have built a good model for green house gas emission let's to deploy this model. One popular mechanism for deploying (or serving) a model is using a REST API. Deploying a model as an API means that we create a webserver with a url that accepts requests. End users or "clients" can make requests to the API and pass a list of data points containing features (usually as json). This list of features is fed into the model and the model spits out a list of predictions corresponding to those features. These list of predictions are sent back to the client (again usually as json).
The first step in the process is to save the model using the XGBoost module:
import mlflow.xgboost
model = mlflow.xgboost.load_model("XGBModel")
This creats a folder similar to the LinerModel one we discussed above. The next step is to use the MLflow commnand line to serve the model. From the directory where we saved the above model we can use the command:
mlflow models serve --m XGBModel
This will initially show the following:
If everything builds properly we will then see the following:
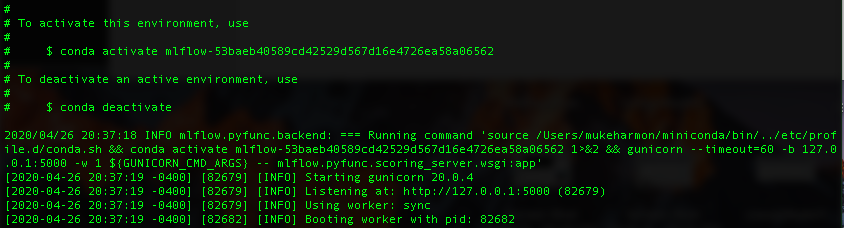
Notice the "Listening at: http://127.0.0.1:5000", this is the url for our webserver. We will make requests to get model predictions at the url. We have built a REST API that uses flask and gunicorn with a one line command using MLflow! To see how difficult this be to do by hand see my other github repo.
Let's get some test data to try out model REST API:
test_df = X_test.head(2)
test_df
Let's get the predictions that the XGBoost model gives us as is to what the REST API returns:
xgb_model.predict(test_df)
Now let's convert the test data from a Pandas dataframe to json:
test_json = test_df.to_json(orient='split')
test_json
We can submit the json as request for predictions to the REST API:
import requests
result = requests.post(url="http://127.0.0.1:5000/invocations",
data=test_json,
headers={'Content-Type':'application/json'})
result.json()
The results are the same! Now let's take this one step further and use MLflow to build a Docker image so that we can deploy our REST API as a container. This again, is only one lineand that command is,
mlflow models build-docker -m XGBModel -n xgbmodel
Where the xgbmodel is the tag for the Docker image and XGBModel is the folder we saved our model as. If the image is built properly we can see the following:

The image is fafed3745d54 and the tag is xgbmodel:latest. We can start up our containerized REST API using the command:
docker run -ip 8000:8080 fafed3745d54
The -p 8000:8080 is for port forwarding. Notice that we have to use 8000 because the the results show:
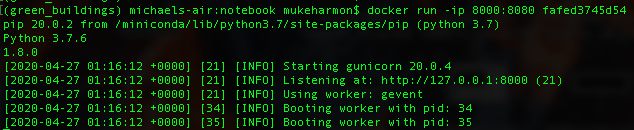
We can the make a request to that url and port:
result = requests.post(url="http://127.0.0.1:8000/invocations",
data=test_json,
headers={'Content-Type':'application/json'})
result.json()
The reults are the same as expected!
There is one downside for using MLflow to build a docker image and that is your image turns out to be quite large. We can see this from the command:
docker images
which shows,

Our model takes up 2.72 GB!
6. Deploying to Google App Engine with Docker ¶
We have come to the last topic of this post which is deploying our model as REST API to the cloud. We can easily deploy the "Dockerized" model API to Google Cloud App Engine using the Docker image we created.
The first step is to follow the instructions here for copying the local Docker image to Google Cloud Registry (GCR). For me the command was :

Once that is done we can check GCR to make sure the image has been pushed, you can see the results below:

Next I built the app.yaml for a custom runtime and using flexibly environment as described here. The contents of my app.yaml are:
runtime: custom
env: flex
service: xgbmodel
env_variables:
DISABLE_NGINX: "true"
It's important to note using the container will start nginx and gunicorn processes which we DO NOT want and therefore chose DISABLE_NGINX: "true" as discussed here.
I then ran the command to deploy the app (gcloud app deploy) using --image-url with the address for my image in GCR:
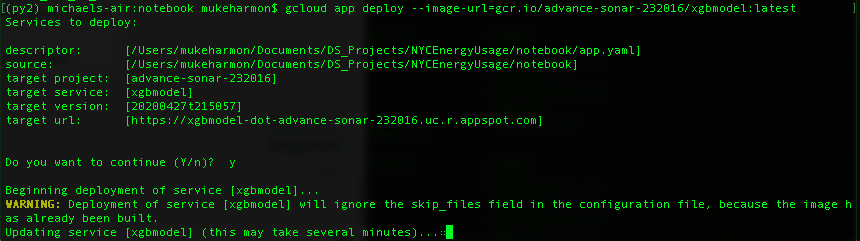
One everything is completed I can check my app was created in the App Engine tab:
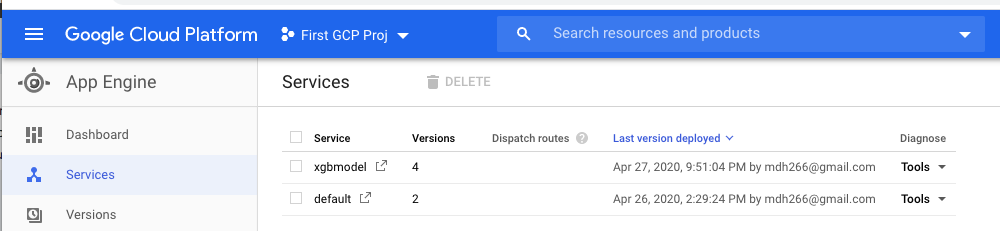
Now I can use the target url as pictured above to run a request against as shown below:
target_url = "https://xgbmodel-dot-advance-sonar-232016.uc.r.appspot.com/invocations"
result = requests.post(url = target_url,
data = test_json,
headers = {'Content-Type':'application/json'})
result.json()
It worked! To see how difficult this be to do by hand see my other github repo. That's enough for this post!
Conclusions ¶
This blog post ends the series of blog posts that starts with a real life dataset on building energy usage and green house gas emissions. In previous posts we covered cleaning the dataset, but in this blog post we covered using the cleaned dataset and building a model with $R^2 \, = \, 0.776$ and deploying it to Google App Engine as an API using Docker. This process was made signifcantly easier using the MLflow library for model development and serving. This project was a lot of fun and I learned a ton workng on it. I hope you found this useful!