Creating An AI-Based JFK Speech Writer: Part 2¶
Introduction ¶
In this blog post I follow up on the last post and develop a model for text generation using Recurrent Neural Networks. I'll build a bi-directional gated recurrent unit (GRU) that is trained on speeches made by President John F. Kennedy. Specifically, I'll go over how to build a model that predicts the "next word" in a sentence based off a sequence of the words coming before it. This project was more challenging than I initially anticipated due to the data preparation needs of the problem as well as the fact the performance is hard to quantify. The data preparation was more involved then other posts that I have done on natural language processing since it involves modeling a sequences of words instead of using a "bag-of-words." I'll go over some of these details more in the post.
The concept of sequence modeling in recurrent neural networks is also different from other models that I have done in the past and I will spend some time covering this topic. Interestingly, the next word prediction turns out to be a multi-class classification problem, albeit with a very large number of classes! Let's get started with the problem.
The first step is to import the necessary TensorFlow and Google Cloud Python packages (since the data is in Google Cloud Storage) :
import numpy as np
import tensorflow as tf
from google.oauth2 import service_account
from google.cloud import storage
tf.compat.v1.logging.set_verbosity('ERROR')
tf.config.list_physical_devices('GPU')
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
print(tf.__version__)
2.9.0
Data Preparation ¶
Next I connect to Google Cloud Storage to download all the concatenated speeches by President Kennedy. To do this I get my GCP credentials and then instantiate the client to connect to the bucket gs://harmon-kennedy/
credentials = service_account.Credentials.from_service_account_file('credentials.json')
client = storage.Client(project=credentials.project_id, credentials=credentials)
bucket = client.get_bucket("harmon-kennedy")
Now I can download all the speeches that were concatenated into one file,
blob = bucket.blob("all_jfk_speeches.txt")
text = blob.download_as_text()
I can see the first 300 characters of the text are,
text[:300]
'Of particular importance to South Dakota are the farm policies of the Republican party - the party of Benson, Nixon and Mundt - the party which offers our young people no incentive to return to the farm - which offers the farmer only the prospect of lower and lower income - and which offers the nati'
To get situated with the data I can get the number of characters in the text as well as the number of unique characters,
print(f'Length of text: {len(text)} characters')
Length of text: 7734579 characters
vocab = sorted(set(text))
print(f'{len(vocab)} unique characters')
67 unique characters
Since I'll be making a word level model this isn't totally helpful. Instead I'll get the total number of words and number of unique words. To do this I need to clean the text; convert newline characters to spaces, remove non-English characters and convert characters to lower case.
words = text.replace("\n", " ").split(" ")
clean_words = [word.lower() for word in words if word.isalpha()]
clean_text = " ".join(clean_words)
The impact this had on the same text from above can be seen below,
clean_text[:300]
'of particular importance to south dakota are the farm policies of the republican party the party of nixon and mundt the party which offers our young people no incentive to return to the farm which offers the farmer only the prospect of lower and lower income and which offers the nation the vision of'
The total number of clean words and unique clean words in the text are,
print(f"{len(clean_words)} number of clean words")
1196835 number of clean words
print(f"{len(set(clean_words))} unique clean words")
19291 unique clean words
Now let's talk about how we can process our text data for training a model to predict the next word.
The way a word level text generation model is built is to take a sequence of N words and then predict the next one. To create a training set, the text is split up into sliding widows where the feature vector x is the N words in the sequence of text and the target y is the N+1 word in that text. We repeat this process for N=1,2,3,4,...
For instance take the sentence "the man is walking down the street." To build a model that predicts the next word based on the 4 words that come before it, it is necessary to create the 4 training examples as shown below,
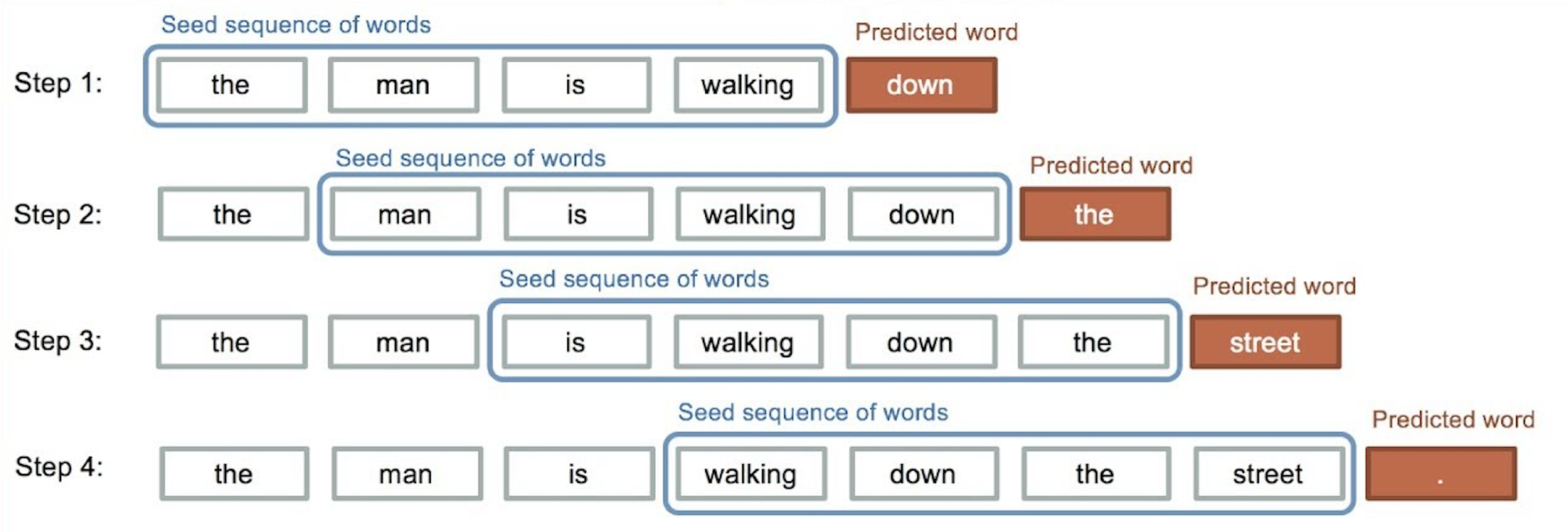
For this model I will use seq_length as N or the number words in the text used to predict the next word. In order to be able to predict the next word I need to reduce the total number words that are possible to predict to a finite number. This means limiting the number of possible words to be a set of size vocab_size. This in turn converts the next word prediction problem into a classification problem with vocab-size classes.
In order to convert the text which is represented as a sequence of words into numerical vectors I'll use the TextVectorization class. This technique is discussed in more in a prior post which you can read here.
vocab_size = 12000
seq_length = 30
I first instantiate the TextVectorization layer and fit it to the text:
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
vectorizer_layer = TextVectorization(
standardize="lower_and_strip_punctuation",
max_tokens=vocab_size,
output_mode="int",
output_sequence_length=seq_length,
)
vectorizer_layer.adapt([clean_text])
2024-01-28 17:07:18.274711: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
Note that I do this on the clean_text string and not the text string.
I can then get the set of words in the vectorizer_layer's "vocabulary" and create a dictionary to look up each word's equivalent numerical value.
voc = vectorizer_layer.get_vocabulary()
word_index = dict(zip(voc, range(len(voc))))
We can see the vocab size of the vectorizer_layer,
len(voc)
12000
The numerical value for each of the first two words in the example text above is then,
word_index['of']
3
word_index['particular']
717
The numerical value for the "out of vocabulary" token is,
word_index['[UNK]']
1
Next I'll create the dataset X and y, where X is the vector of features, which in turn are numerical values for the sequence of words. The vector y is the target which consist of integers that represents the numerical value of next word in the corresponding sequence in X:
words_seq = [clean_words[i:i + seq_length] for i in range(0, len(clean_words) - seq_length-1)]
next_word = [clean_words[i + seq_length] for i in range(0, len(clean_words) - seq_length-1)]
2024-01-28 17:07:21.834528: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:07:21.836850: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
Each entry in words_seq is a list of the seq_length words or tokens that make up the sequence in that training example.
for words in words_seq[:2]:
print(" ".join(words) + "\n")
of particular importance to south dakota are the farm policies of the republican party the party of nixon and mundt the party which offers our young people no incentive to particular importance to south dakota are the farm policies of the republican party the party of nixon and mundt the party which offers our young people no incentive to return
Now I'll convert the target vector of "next words" to a vector with "numerical values" using the word_index dictionary:
next_cat = np.array([word_index.get(word, 1) for word in next_word])
next_cat[:2]
array([978, 5])
Notice that if the word is not in the word_index then it is given the out of vocabulary int of 1.
Then I convert those list of lists into a list of strings,
X = np.array([" ".join(words_seq[i]) for i in range(len(next_word))
if next_cat[i] != 1]).reshape(-1,1)
X[:2]
array([['of particular importance to south dakota are the farm policies of the republican party the party of nixon and mundt the party which offers our young people no incentive to'],
['particular importance to south dakota are the farm policies of the republican party the party of nixon and mundt the party which offers our young people no incentive to return']],
dtype='<U260')
The reason for doing this is that this way my model will be able to take inputs that are just plain text instead of needing lists of strings that represent that text. The later would require that new inputs to the model be pre-processed before being feed into the trained model, while the latter means a trained model can just take raw text as the input.
Notice that I only included sequences of the text where the target word was not an out of vocabulary word.
The next two words that correspond to the targets for the examples above are,
next_word[:2]
['return', 'to']
Lastly, I'll create the target vector by filtering out the case where value would be out-of-vocabulary tokens:
y = np.array([cat for cat in next_cat if cat != 1])
y[:2]
array([978, 5])
The reason for filtering the out-of-vocabulary tokens is I don't want to train a model that predicts out-of-vocabulary words since this would be meaningless to end users.
The size of the X dataset is,
X.shape
(1187726, 1)
That is X is technically a 1-D array, but each entry in X is an array that contains the string of text. Once we transform the X array we will have a matrix it will be of size,
vectorizer_layer.call(X).shape
TensorShape([1187726, 30])
This is what we would expect, 50 features per entry in our design matrix. Again, I use this set up where X is a 1 dimensional array so that my model has only input of text.
The target variable has shape,
y.shape
(1187726,)
Now to see what effect the vectorizer layer has on the text I'll feed the first two sequences above through the layer.
vectorizer_layer.call(X[:2])
<tf.Tensor: shape=(2, 30), dtype=int64, numpy=
array([[ 3, 717, 652, 5, 482, 2772, 16, 2, 143, 280, 3,
2, 142, 81, 2, 81, 3, 192, 4, 8230, 2, 81,
23, 1290, 13, 406, 57, 46, 3001, 5],
[ 717, 652, 5, 482, 2772, 16, 2, 143, 280, 3, 2,
142, 81, 2, 81, 3, 192, 4, 8230, 2, 81, 23,
1290, 13, 406, 57, 46, 3001, 5, 978]])>
The vectorizer layer converts the array of strings with shape (1179990,) to an matrix of integers of shape (1179990, seq_length). Each entry in the array will be a integer from 1 to vocab_size and is the integer representation for each word.
Now that we an understanding of how we can create the dataset let's talk about Recurrent Neural Networks.
A Bidirectional GRU Model ¶
Recurrent Neural Networks (RNN) are deep learning models used to predict sequences. These models use an internal state, h, to act as memory that processes these sequences and "remember" things from the past. A quintessential diagram of a RNN is shown below,
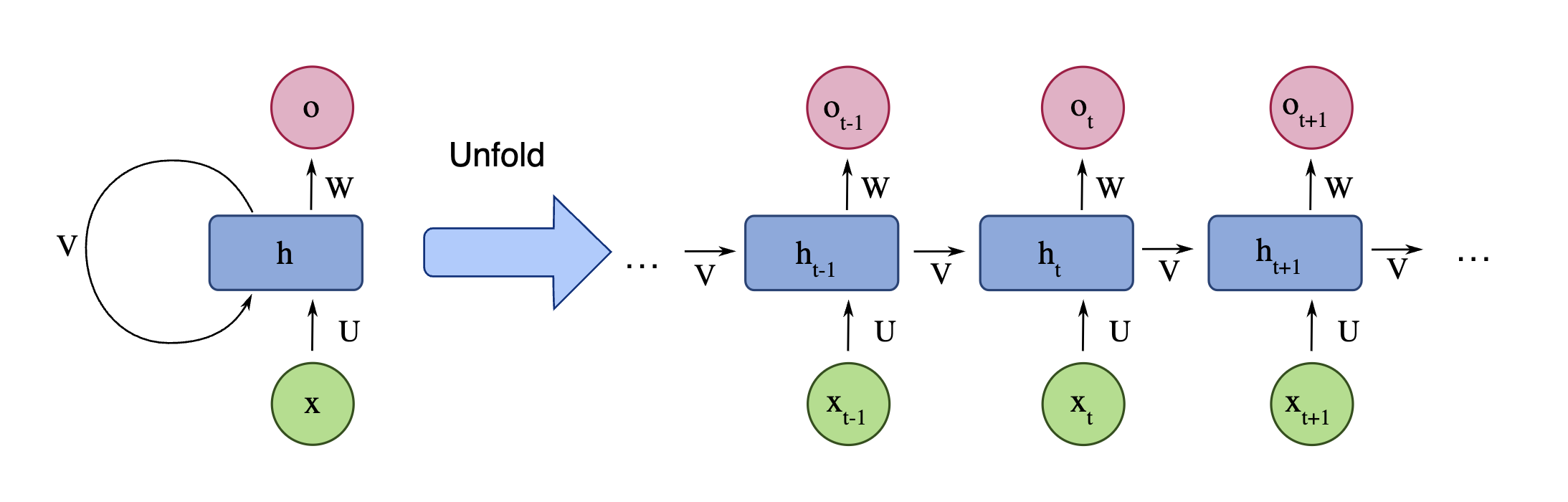
A RNN cell is shown on the left and on the right is the "un-rolled" version that shows how the cell processes a sequence of inputs x into outputs o; there is a subscript t that denotes entry in the sequence. The subscript for each h is used to denote the value the internal state or memory cell in the t-th entry in the sequence.
There are a number of RNN's and a few are shown below,
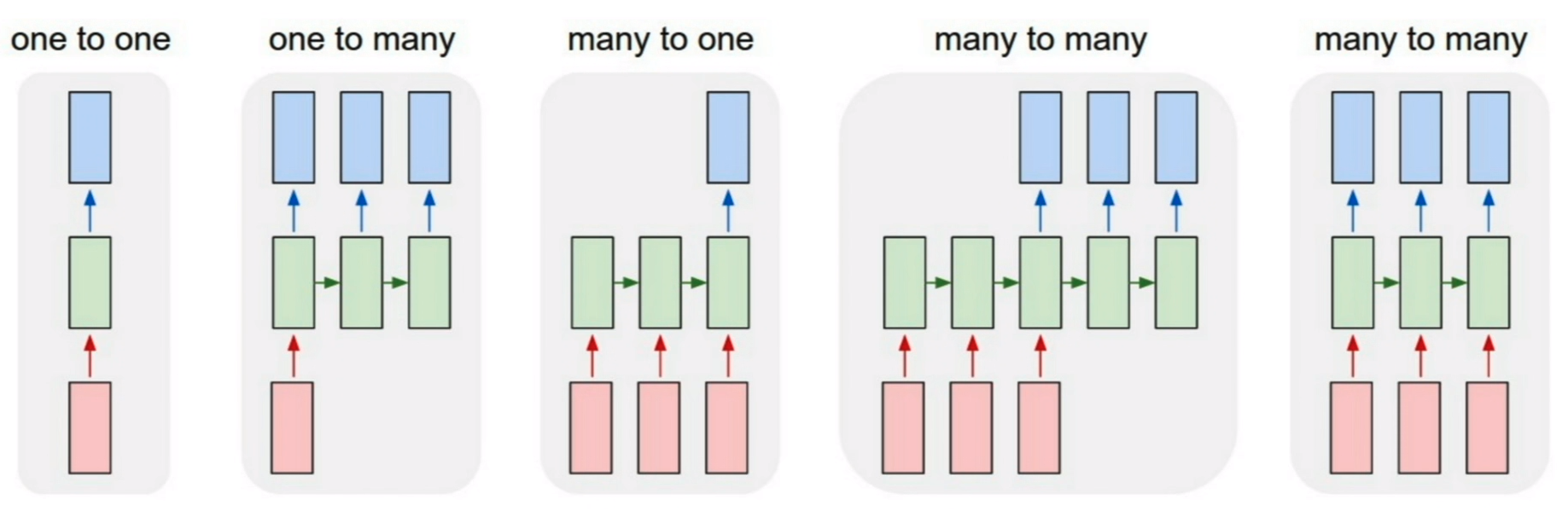
The model I am building in this post that uses a sequence of words to predict the next word is a "many-to-one" model. The many-to-one RNN gets its name since we using a sequence "many" of word to predict one word, i.e. the next word. Zooming into the RNN cell we focus on a specific type of RNN called a Gated Recurrent Unit (GRU). The details of a GRU cell are shown below.
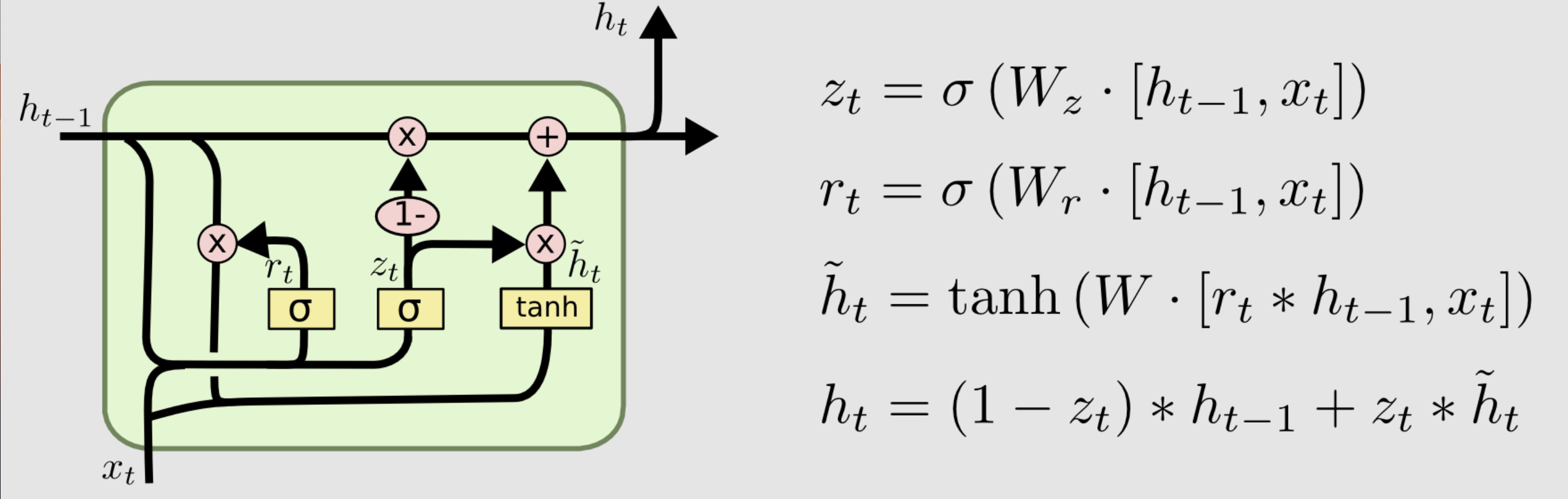
There is a hidden state h that takes on values for each iteration t. There is a candidate update to the hidden state h with a ~ over it. The candidate update to the hidden state has values between -1 and +1 and is a function of the relevance gate r as well as the prior value of the hidden state and the current value of the input. The relevance gate is value between 0 and 1 and is a function of the prior value of the hidden state and the current value of the input. It controls the amount off effect that the prior hidden state value has on the candidate update value for the hidden state.
Lastly, there is a forget gate z which is between 0 and 1 is a function of the prior value of the hidden state and the current value of the input. The forget gate is used to control whether we update the hidden state value or not. If z = 1 then we update the internal state to be the candidate state. If z = 0, the value for the hidden state remains unchanged.
Notice the hidden state value h of one iteration can be fed directly into the RNN as well as the input x. These variables are not necessarily scalars and are often vectors.
In the model I am building the variables will be vectors of dimension seq_length. The output of the RNN cell is a vector of size vocab_size. To convert the hidden state vector x to y we apply a softmax function.
Many times in natural language processing models make use of a bi-directional RNN. In this type of model two RNN cells are used, one processing the sequence in the forward direction and one processing the sequence in the reverse direction. The architecture is shown below:
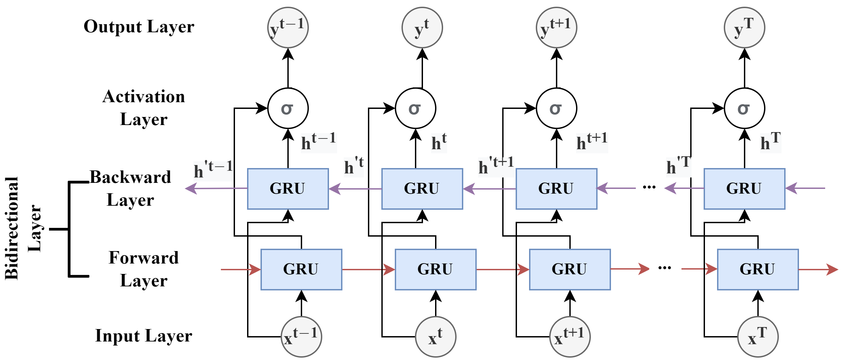
Notice that the forward and backward GRU cells are both a function of the same input value x (both at the same time t), but are functions of different iterations hidden states h (different values of t). Both cells at the same iteration are used to compute the output at the same iteration. Bidirectional RNN's were introduced to increase the amount of input information available to the network.
I had originally created a bi-directional GRU model using TensorFlow's subclassing, however, I ran into issues with the size of this dataset and shuffling the data. It was hard to shuffle the entire Pandas dataframe and then train on it, so instead I looked to using the the TensorFlow Dataset module.
This allows me to "stream" over the dataset, shuffle and mini-batch it using the from_tensor_slices to convert the Pandas DataFrame and Series tuple to a TensorFlow dataset.
dataset = (tf.data.Dataset
.from_tensor_slices((X, y))
.shuffle(50000)
.batch(128))
Next, I built a function which creates a sequential model which contains a TextVectorization layer, followed by an Embedding layer, Bidirectional GRU layer, and finally a dense layer with a softmax activation layer.
I compile the model using the SparseCategoricalEntropy loss function since the target variable has not been one-hot-encoded and use the Adam optimization algorithm with and learning rate that has exponential decay. Since we are using this as a model to predict the next word, the correct answer is a somewhat subjective and I don't care too much about which metric we use to measure performance.
I wrote this as function that returns both the fitted vectorizer layer as the compiled Keras model. I need the vectorizer layer so that I have a mapping that convert the predicted numerical "next word" into actual text.
from typing import Tuple
def build_model(
text: str,
seq_length: int,
vocab_size: int,
embedding_dim: int,
units: int
) -> Tuple[TextVectorization, tf.keras.models.Sequential]:
vectorizer_layer = TextVectorization(
standardize="lower_and_strip_punctuation",
max_tokens=vocab_size,
output_mode="int",
output_sequence_length=seq_length)
vectorizer_layer.adapt([text])
model = tf.keras.models.Sequential([
tf.keras.Input(shape=(1,),
dtype=tf.string,
name='text'),
vectorizer_layer,
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.Bidirectional(tf.keras.layers.GRU(units)),
tf.keras.layers.Dense(vocab_size, activation='softmax')
])
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate=1e-1,
decay_steps=1000,
decay_rate=0.001)
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer=tf.optimizers.Adam(learning_rate=lr_schedule))
return vectorizer_layer, model
I can create a model that has takes in relatively short text of 20 words and predicts the next out of 15,000 possibilities. The embedding layer has 128 dimensions and the Bidirectional GRU layer has 64 units each:
vectorizer, model = build_model(text=text,
seq_length=seq_length,
vocab_size=vocab_size,
embedding_dim=128,
units=64)
2024-01-28 17:07:48.997658: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
Notice that for the vectorizer layer I have to pass the original text, seq_length and the vocab_size values to initialize that layer properly. I can get the summary of the model:
model.summary()
Model: "sequential_19"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization_30 (Text (None, 30) 0
Vectorization)
embedding_19 (Embedding) (None, 30, 128) 1536000
bidirectional_19 (Bidirecti (None, 128) 74496
onal)
dense_19 (Dense) (None, 12000) 1548000
=================================================================
Total params: 3,158,496
Trainable params: 3,158,496
Non-trainable params: 0
_________________________________________________________________
The model has over 3 million parameters which is a lot!
Now I can train the model on the dataset with a modest 3 epochs:
history = model.fit(dataset, epochs=3)
Epoch 1/3
2024-01-28 17:07:57.527292: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:07:57.777102: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:07:57.794880: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:07:58.171041: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:07:58.184822: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
9280/9280 [==============================] - 474s 51ms/step - loss: 7.5869 Epoch 2/3 9280/9280 [==============================] - 465s 50ms/step - loss: 7.3280 Epoch 3/3 9280/9280 [==============================] - 477s 51ms/step - loss: 7.3280
Now I can save the model for future use:
model.save("jfk_model")
WARNING:absl:Found untraced functions such as gru_cell_61_layer_call_fn, gru_cell_61_layer_call_and_return_conditional_losses, gru_cell_62_layer_call_fn, gru_cell_62_layer_call_and_return_conditional_losses while saving (showing 4 of 4). These functions will not be directly callable after loading.
I can reload the model (at another time) as shown below,
model = tf.keras.models.load_model("jfk_model")
2024-01-28 17:42:19.454192: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:42:19.459024: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
I can predict the next word in the sequence from one of the training examples,
X[0]
array(['of particular importance to south dakota are the farm policies of the republican party the party of nixon and mundt the party which offers our young people no incentive to'],
dtype='<U260')
np.argmax(model.predict([X[0]]))
2024-01-28 17:42:20.799824: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:42:20.864376: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled. 2024-01-28 17:42:20.870536: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:113] Plugin optimizer for device_type GPU is enabled.
1/1 [==============================] - 0s 474ms/step
2
We can then create the mapping to look up the text associated with the numerical value of the next word from the vectorizer layer.
voc = vectorizer.get_vocabulary()
word_index = dict(zip(voc, range(len(voc))))
reverse_word_map = dict(map(reversed, word_index.items()))
str(reverse_word_map[
np.argmax(
model.predict(X[0])
)
])
1/1 [==============================] - 0s 101ms/step
'the'
We did not get the correct word, this can happen.
Generating Text ¶
Now that the model can generate the next word based on the 30 preceding words we can use it to create text.
I'll use an in-sample JFK speech at first:
test = X[3342][0]
print(test)
fails to recognize that the problems of one industry may be different from it completely fails to respect the traditional practices widely accepted in the building it completely fails to
Now I can generate the next best n-words using a greedy algorithm defined below:
def next_words_greedy(input_str: str, n: int) -> str:
final_str = ''
for i in range(n):
prediction = model.predict(np.array([input_str]), verbose=0)
idx = np.argmax(prediction[0])
next_word = str(reverse_word_map[idx])
final_str += next_word + ' '
input_str += ' ' + next_word
input_str = ' '.join(input_str.split(' ')[1:])
return final_str
The above function repeatedly adds the next most probable word to the sentence.
Let's see the results:
next_words_greedy(test, 3)
'invited the much '
This doenst quite make sense. Choosing the next best word at each step can give us poor results as the sentence might not make sense and often leads to repeated words.
There a few ways to generate more realistic sentences, one of them being beam search algorithm. I actually tried using this method with KerasNLP, but had a bunch of issues and could not get it to work.
So instead I wanted to look at adding some randomness to the next best word algorithm. One way to do this is by choosing the next word by sampling the predicted distribution of words based on their probabilities. I used the choice method from NumPy to accomplish this below,
def next_words_distribution(input_str: str, n: int) -> str:
final_str = input_str + ' '
for i in range(n):
prediction = model.predict(np.array([input_str]), verbose=0)
idx = np.random.choice(vocab_size, p=prediction[0])
next_word = str(reverse_word_map[idx])
final_str += next_word + ' '
input_str += ' ' + next_word
input_str = ' '.join(input_str.split(' ')[1:])
return final_str
Now let's test it out:
next_words_distribution(test, 10)
'fails to recognize that the problems of one industry may be different from it completely fails to respect the traditional practices widely accepted in the building it completely fails to attorney shall at to hospital that attract on a demand '
This again doesn't quite make too much sense. Building a JFK speech writter from scratch is not as easy as I thought!
I spent a lot of time tweeking the model to no avail. Instead I think I will stop persuing this architecture and instead use a more modern one in another blog post.
Next Steps ¶
In this blog post I covered how to create a generative text model using bi-directional gated recurrent unit (GRU) that is trained on speeches made by President John F. Kennedy. The model was built in Keras using TensorFlow as a back-end and I covered how to use this model to generate text based off an input string.
The GRU model is a specific type of Recurrent Neural Network (RNN) and models sequences. RNNs were quite popular for Natural Language Processing until around 2017/2018. More recently, Recurrent Neural Networks have fallen out of popularity for NLP tasks as Transformer and Attention based methods have shown substantially better performance. Using transformers for generating text that is meant to sound like JFK would be a natural next step and will be a follow up for a future blog post!