1. Introduction to RAG ¶
In my last post on RAG I discussed how to ingest President Kennedy's speeches into a Pinecone vector database and perform semantic search using both Pinecone's API as well as using the Langchain API. I used Pinecone for a vector database since its cloud based, fully managed and of course has a free tier. In this post I will expand upon my prior work and build out a Retrivial Augmented Generation (RAG) pipeline using Langchain. I will deploy this as a Streamlit application to be able to answer questions on President Kennedy.
You may ask what is the point of RAG pipelines? Don't Large Language Models (LLMs) know answers to everything? The answer is most LLMs take a long time to train and are often trained on data that is out of date when people begin to use the model. In order to incorporate more recent data into our LLM we could use fine-tuning, but this can still be time consuming and costly. The other option is to use Retrivial Augmented Generation (RAG). RAG takes your original question and "retrieves" documents from a vector database that are most most semantically related to your qeustion. RAG is able to do semantic search by converting the text in your question and the documents to a numerical vectors using an embedding. The closeness of the document vectors to the question vector (with resepect to a norm) measures the semantic similarity. The original question and the retrieved documents are incorporated into a prompt which is fed into the LLM where they are used as "context" to generate an answer. The entire process is depicted below,
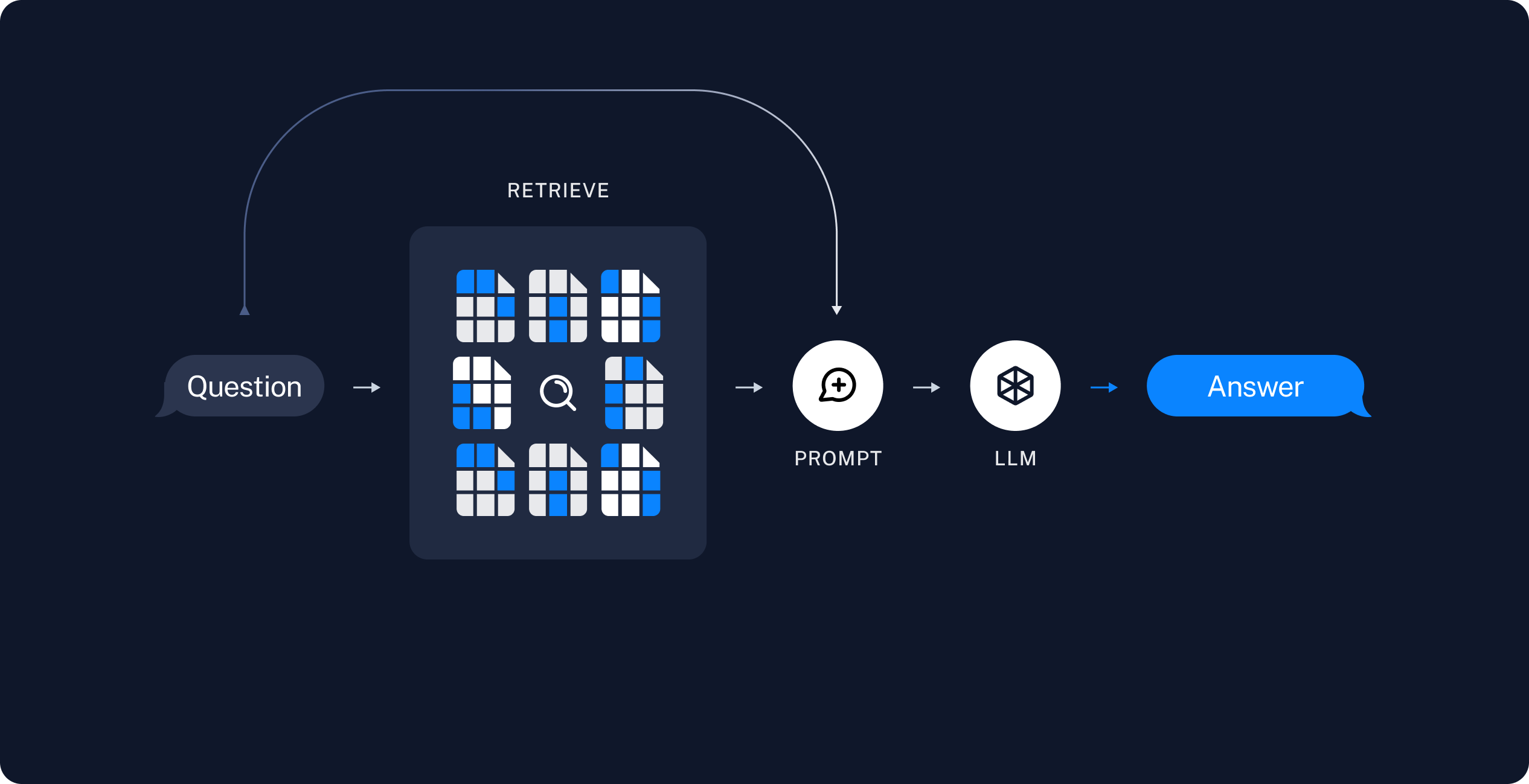
I'll note that building a RAG pipeline was actually much easier than I originally thought which is a testament to the power and simplicity of the Langchain framework!
Let's get started!
I'll start out with all the necessary imports:
# LangChain
from langchain.chains.retrieval import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
from langchain_groq import ChatGroq
from langchain_pinecone import PineconeVectorStore
# Pinecone VectorDB
from pinecone import Pinecone
from pinecone import ServerlessSpec
import os
# API Keys
from dotenv import load_dotenv
load_dotenv()
True
2. Retriving Documents With Vector (Semantic) Search ¶
First thing we'll do is review retrivial with semantic search again. This is important since I will dicuss a more useful way to interact with the Vector databse using a so-called "retrivier." This functionality will be particularly helpful for a RAG pipeline.
The first thing I need to do is connect to the Pinecone database and make sure the index of vectors corresponding to President Kennedy's speches exists:
index_name = "prez-speeches"
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
pc.list_indexes()
[
{
"name": "prez-speeches",
"metric": "cosine",
"host": "prez-speeches-2307pwa.svc.aped-4627-b74a.pinecone.io",
"spec": {
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
},
"status": {
"ready": true,
"state": "Ready"
},
"vector_type": "dense",
"dimension": 2048,
"deletion_protection": "disabled",
"tags": null
},
{
"name": "jfk-speeches",
"metric": "cosine",
"host": "jfk-speeches-2307pwa.svc.aped-4627-b74a.pinecone.io",
"spec": {
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
},
"status": {
"ready": true,
"state": "Ready"
},
"vector_type": "dense",
"dimension": 2048,
"deletion_protection": "disabled",
"tags": null
}
]
Now that we have confirmed the index exists and is ready for querying we can create the initial connection to the Vector database using the Langchain PineconeVectorStore class. Note that we have to pass the name of the index as well as the embeddings to the class' constructor. It's important that we use the same embeddings here that we used to convert the speeches to numerical vectors in the Pinecone index.
embedding = embedding = NVIDIAEmbeddings(
model="nvidia/llama-3.2-nv-embedqa-1b-v2",
api_key=os.getenv("NVIDIA_API_KEY"),
dimension=2048,
truncate="NONE")
vectordb = PineconeVectorStore(
pinecone_api_key=os.getenv("PINECONE_API_KEY"),
embedding=embedding,
index_name=index_name
)
/Users/mikeharmon/miniconda3/envs/llm_env/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
Now we can perform vector similarity search using the similiarity search function in Langchain. Under the hood this function creates a vector embedding of your question (query) and finds the closest documents using the cosine similiarity score between the embedded question vector and the embedded document vectors. The determination of closest documents to the question are calculated by the "nearest neighbors" algorithm. This process is depicted in image below,
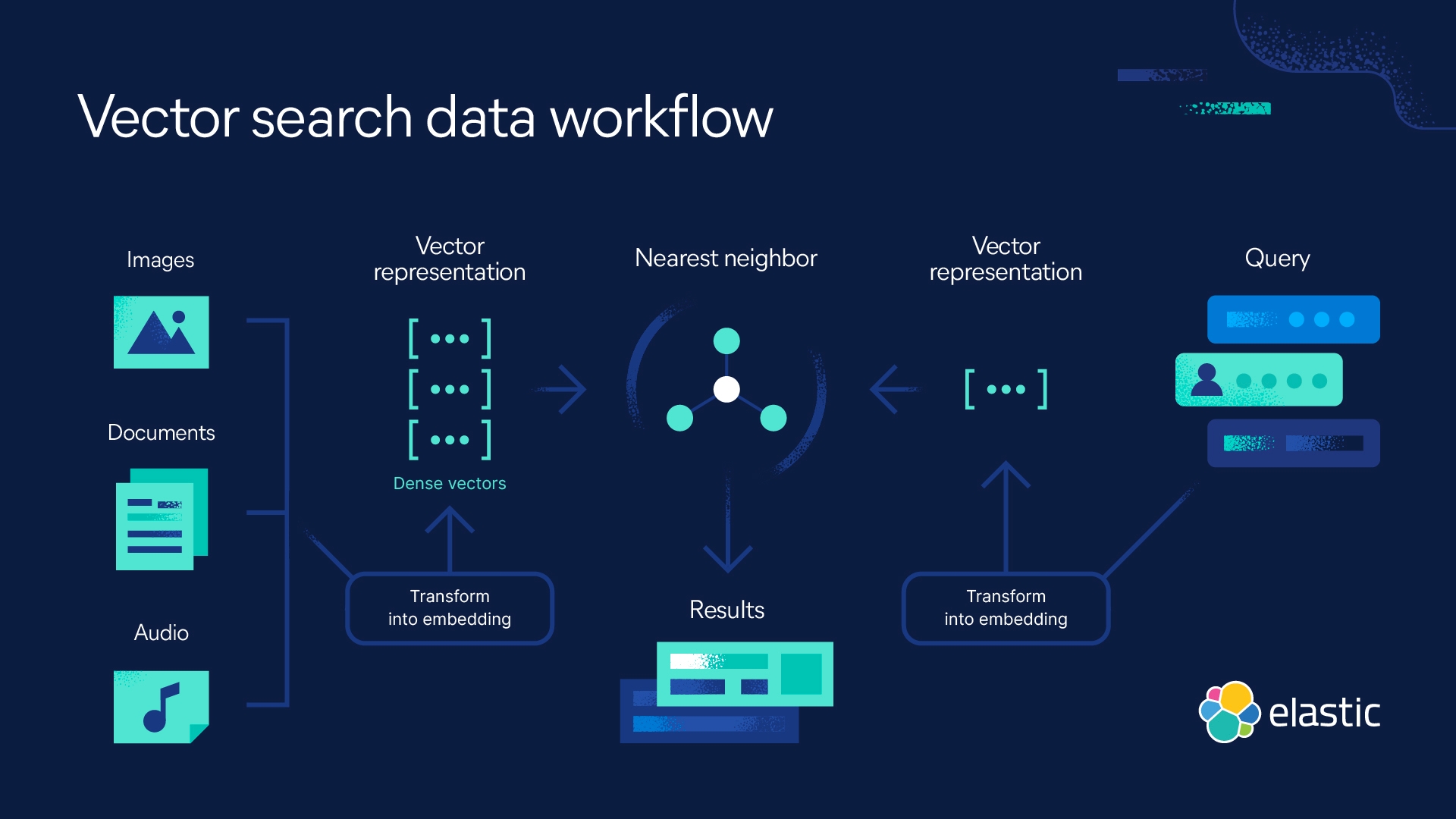
The one thing to note is that I use the async similarity search for funsies and set it to return the top 5 documents.
question = "How did President Kennedy feel about the Berlin Wall?"
results = await vectordb.asimilarity_search(query=question, k=5)
I'll print out the document id's since the actual text for the top 5 will be too long for the screen.
for document in results:
print("Document ID:", document.id)
Document ID: d0245e9a-b4f2-46e6-a6d0-07ee3afbad16 Document ID: b9e573a6-d9f9-4306-a6e3-72ac769643dd Document ID: a6bcd4fa-90a3-46b2-a48d-105115ccaed7 Document ID: ffe2db4a-6983-4cde-a853-658080619575 Document ID: b909248f-495d-4819-9776-d512e7c545f1
Now that we understand how to use the vector database to perform "retrivial" using similairty search, let's create a chain that will allow us to query the database and generate a response from the LLM. This will form the basis of a so-called "RAG Pipeline."
3. Building A RAG Pipeline ¶
Now we can use the vector database as a retriever which is a special Langchain Runnable object that takes in a string (query) and returns a list of Langchain Documents. This is depicted below,
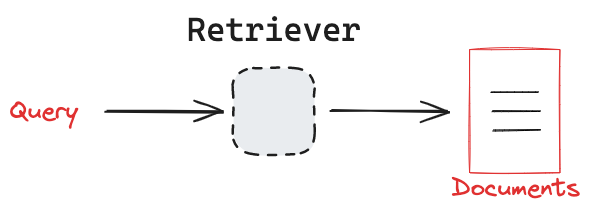
We can see this in action,
retriever = vectordb.as_retriever()
print(type(retriever))
<class 'langchain_core.vectorstores.base.VectorStoreRetriever'>
Now we can query the vector database using the invoke method of the retriever:
documents = retriever.invoke(input=question)
for document in documents:
print("Document ID:", document.id)
Document ID: d0245e9a-b4f2-46e6-a6d0-07ee3afbad16 Document ID: b9e573a6-d9f9-4306-a6e3-72ac769643dd Document ID: a6bcd4fa-90a3-46b2-a48d-105115ccaed7 Document ID: ffe2db4a-6983-4cde-a853-658080619575
Now let's talk about our prompt for RAG pipeline.
I used the classic rlm/rag-prompt from LangSmith. I couldn't use the original one as the function create_retrieval_chain expects the human input to be a variable input while the original prompt has the input be question. The whole prompt is,
from langchain.prompts import PromptTemplate
template = """You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {input}
Context: {context}
Answer:
"""
prompt = PromptTemplate(
template=template,
input_variables=["input", "context"],
)
Now I'll give an example of how to use this prompt. I'll use the question from the user as well as the documents retrieved from Pinecone as context:
print(
prompt.invoke({
"input": question,
"context": [document.id for document in documents]
}).text
)
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise. Question: How did President Kennedy feel about the Berlin Wall? Context: ['d0245e9a-b4f2-46e6-a6d0-07ee3afbad16', 'b9e573a6-d9f9-4306-a6e3-72ac769643dd', 'a6bcd4fa-90a3-46b2-a48d-105115ccaed7', 'ffe2db4a-6983-4cde-a853-658080619575'] Answer:
Note I only used the document ids as context in the prompt. This is because printing the actual Langchain Documents would be a lot of text for the screen. However, in a real RAG pipeline we would pass the actual documents to the LLM.
Now we'll move on to create our LLM ChatModel as this object will be needed to write the response to our question.
llm = ChatGroq(model="llama-3.3-70b-versatile", temperature=0)
The LLM will be used as the generative part of the RAG pipeline.
The generative component in our RAG pipelien will be created by a function called create_stuff_documents_chain. This function will return a Runnable object and we'll give this object the name generative_chain:
generate_chain = create_stuff_documents_chain(llm=llm, prompt=prompt)
We can see what makes up this composite Runnable and the components of the chain:
print(generate_chain)
bound=RunnableBinding(bound=RunnableAssign(mapper={
context: RunnableLambda(format_docs)
}), kwargs={}, config={'run_name': 'format_inputs'}, config_factories=[])
| PromptTemplate(input_variables=['context', 'input'], input_types={}, partial_variables={}, template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {input} \nContext: {context} \nAnswer:\n")
| ChatGroq(client=<groq.resources.chat.completions.Completions object at 0x128d7ffd0>, async_client=<groq.resources.chat.completions.AsyncCompletions object at 0x12fd8b990>, model_name='llama-3.3-70b-versatile', temperature=1e-08, model_kwargs={}, groq_api_key=SecretStr('**********'))
| StrOutputParser() kwargs={} config={'run_name': 'stuff_documents_chain'} config_factories=[]
Now we can call the chain using the invoke method and see the answer to our question.
The chain takes in the prompt as input, passes it to the LLM and then the StrOutputParser which will return a string from the LLM instead of the AIMessage (which is the usual return type of a ChatModel).
answer = generate_chain.invoke(
{
'context': documents,
"input": question
}
)
print(answer)
President Kennedy felt strongly against the Berlin Wall, calling it "an offense not only against history but an offense against humanity" that separates families and divides a people. He saw it as a demonstration of the failures of the Communist system and a threat to freedom. Kennedy emphasized the importance of defending West Berlin and upholding the commitment to its people, stating "we shall not surrender" and seeking peace without surrendering to Communist pressures.
Now we can put this all together as a RAG chain by passing the Pinecone Vector database retriever and the generative chain to the create_retrieval_chain. The retriever will take in the input question and perform similarity search and return the documents. These documents along with the input question will be passed to the generate_chain to return the answer output.
The full RAG chain is below:
rag_chain = create_retrieval_chain(
retriever=retriever,
combine_docs_chain=generate_chain)
The definition of the rag_chain is a bit different from generate_chain above and we can see its compontents,
print(rag_chain)
bound=RunnableAssign(mapper={
context: RunnableBinding(bound=RunnableLambda(lambda x: x['input'])
| VectorStoreRetriever(tags=['PineconeVectorStore', 'NVIDIAEmbeddings'], vectorstore=<langchain_pinecone.vectorstores.PineconeVectorStore object at 0x11cf39e50>, search_kwargs={}), kwargs={}, config={'run_name': 'retrieve_documents'}, config_factories=[])
})
| RunnableAssign(mapper={
answer: RunnableBinding(bound=RunnableBinding(bound=RunnableAssign(mapper={
context: RunnableLambda(format_docs)
}), kwargs={}, config={'run_name': 'format_inputs'}, config_factories=[])
| PromptTemplate(input_variables=['context', 'input'], input_types={}, partial_variables={}, template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {input} \nContext: {context} \nAnswer:\n")
| ChatGroq(client=<groq.resources.chat.completions.Completions object at 0x128d7ffd0>, async_client=<groq.resources.chat.completions.AsyncCompletions object at 0x12fd8b990>, model_name='llama-3.3-70b-versatile', temperature=1e-08, model_kwargs={}, groq_api_key=SecretStr('**********'))
| StrOutputParser(), kwargs={}, config={'run_name': 'stuff_documents_chain'}, config_factories=[])
}) kwargs={} config={'run_name': 'retrieval_chain'} config_factories=[]
We can see prompts that make up this chain:
rag_chain.get_prompts()
[PromptTemplate(input_variables=['page_content'], input_types={}, partial_variables={}, template='{page_content}'),
PromptTemplate(input_variables=['context', 'input'], input_types={}, partial_variables={}, template="You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.\nQuestion: {input} \nContext: {context} \nAnswer:\n")]
And then test it out,
response = rag_chain.invoke({"input": question})
response['answer']
'President Kennedy felt strongly against the Berlin Wall, calling it "an offense not only against history but an offense against humanity" that separates families and divides a people. He saw it as a demonstration of the failures of the Communist system and a threat to freedom. Kennedy emphasized the importance of defending West Berlin and upholding the commitment to its people, stating "we shall not surrender" and seeking peace without surrendering to Communist pressures.'
The response will be a dictionary will look like,
{
'input': -> Input question
'answer' -> LLM answer
'context': -> List of documents
}and contains the input question and the answer generated by the model. It also includes the context for which are all documents that were the most semantically related to our question and passed to the LLM to use to generate an answer.
We can see the associated data with context reference documents which will be important for our deployment. Note to make sure there are not duplicate sources we have to create a set of tuples containing the title and url:
references = {(doc.metadata['title'], doc.metadata['url']) for doc in response['context']}
references
{('Radio and Television Report to the American People on the Berlin Crisis, July 25, 1961',
'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/berlin-crisis-19610725'),
('Remarks of President John F. Kennedy at the Rudolph Wilde Platz, Berlin, June 26, 1963',
'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/berlin-w-germany-rudolph-wilde-platz-19630626')}
4. Deploying A RAG Application ¶
Now in order to deploy this in a Streamlit App I'll create a function that called ask_question that takes in a question and an index_name for the vector database, it then runs all the logic we went through above and returns the response dictionary. I'll then print the answer from the LLM and then print out the retrieved documents as sources for the with the title as the speech and the the url as a hyperlink. The entire streamlit app with an example is shown below,
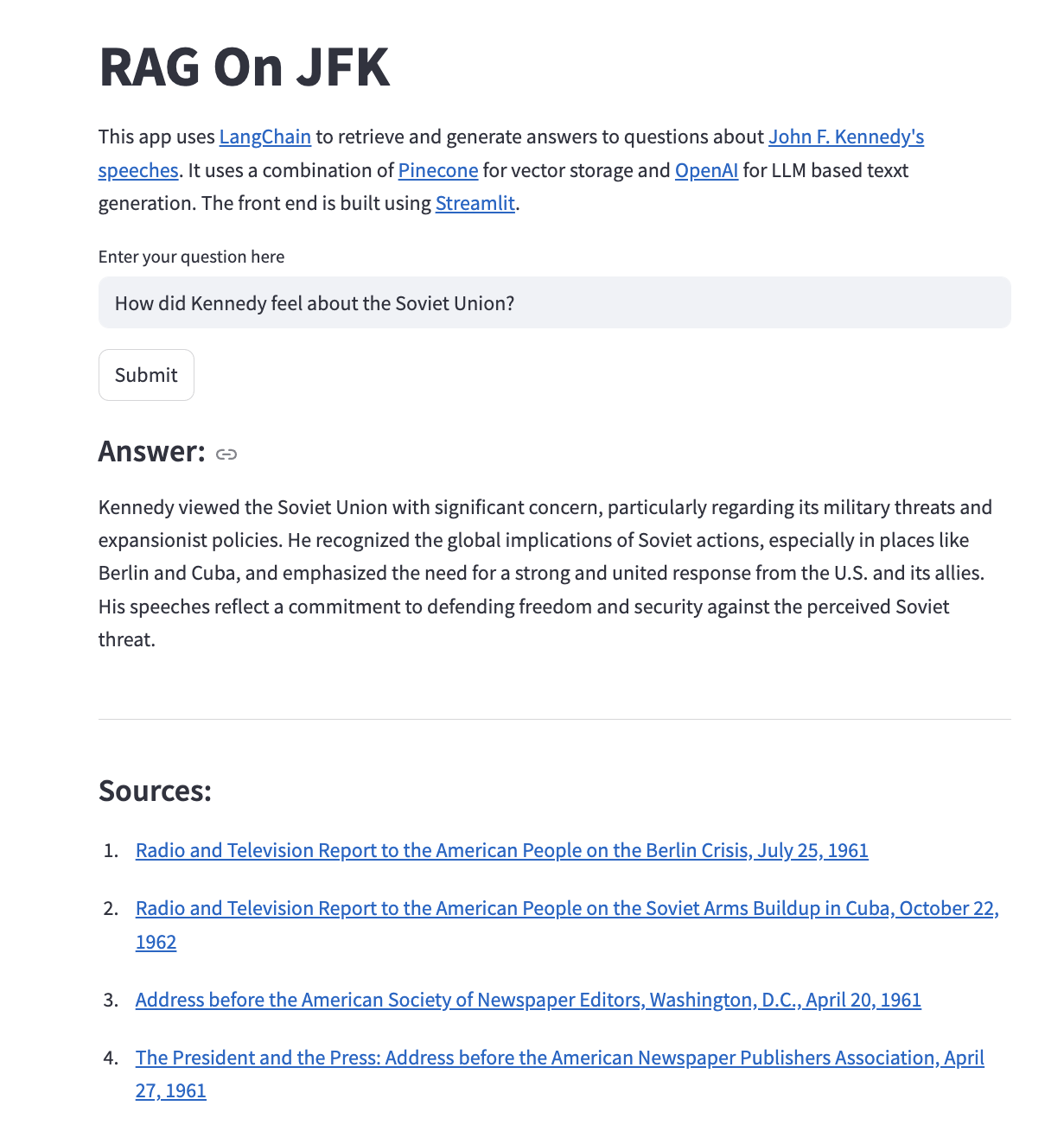
I won't go through the process of deploying this app to Google Cloud Run as I have covered that pretty extensively in a prior post.
5. Conclusions ¶
In this post I covered the basics of creating a Retrivial Augumented Generation (RAG) App using Langchain and deploying it as a Streamlit App. The RAG application is based on Speeches made by President Kenendy and were stored in a Pinecone Vector database. In a future post I will go over methods of evaluating and testing the RAG pipeline, but this is enough for now. Hope you enjoyed it!