Retrievial Augmented Generation On JFK Speeches: Part 1¶
2. Scraping JFK Speeches using Asyncio
3. Loading and Embedding Speeches
1. Introduction ¶
In this post I venture into building a Retrieval Augumented Generation (RAG) application that has been "trained" on President John F. Kennedy speeches. In past posts I covered how I collected JFK speeches and built a "speech writer" using a Gated Recurrent Unit (GRU) Neural Network. In this post I improve upon on the prior work to build a RAG pipeline.
The first thing I will cover is how I collected the data to include extra metadata on speeches as well as using the Asyncio package to reduce run time when writing to object storage. Next, I will go over how to load the json files from Google Cloud Storage using different LangChain loaders. After that I cover how to embed documents and ingest the data into a Pinecone Vector Database. In a follow up post I'll cover how to create and deploy the actual RAG application.
Now I'll import all the classes and functions I will need for the rest of the post.
# LangChain
from langchain_google_community.gcs_file import GCSFileLoader
from langchain_google_community.gcs_directory import GCSDirectoryLoader
from langchain.document_loaders import JSONLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
from langchain_pinecone.vectorstores import PineconeVectorStore
# Google Cloud
import os
from google.cloud import storage
from google.oauth2 import service_account
credentials = service_account.Credentials.from_service_account_file('../credentials.json')
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "../credentials.json"
# Pinecone VectorDB
from pinecone import Pinecone
from pinecone import ServerlessSpec
# API Keys
from dotenv import load_dotenv
load_dotenv()
True
2. Scraping JFK Speeches using Asyncio ¶
In the first post of my work on a speecher writer I covered how to injest the JFK speeches from his presidential library into Google Cloud Storage. I was never completely satisfied with the way I wrote the job before and decided to go back and redo it using the Asyncio library to perform Asynchronous reading of HTML and writing json to Google cloud storage. The json documents include the text of the speech, its title, source and url for the speech. I don't want to go into the details this work, but I will say it was not as hard as I would have thought! The main thing was to turn functions which use the request package into coroutines. Informally, when using requests.get method to scrape the scrape a website, query a REST API or other I/O methods the process is "blocking". This means the Python task is not able to proceed until its receives the return value (or hears back) from the API or website. In the time the program is waiting, the threads and CPU could be doing other work. The Asyncio library allows Python to to free up these idling threads to do other work while waiting for I/O work to complete.
If you are interested in reading more about it the script is here.
3. Loading and Embedding Speeches ¶
At this point I have run the extract.py script which scraped the JFK libary website and converted the speeches into json. The speeches exist as json documents in Google Cloud Storage and in order to ingest it into Pinecone requires the use of the JSONLoader function from LangChain. In addition to loading the documents I also wanted to add metadata to the documents. I did so using LangChain by creating the metadata_func below:
from typing import Dict
def metadata_func(record: Dict[str, str], metadata: Dict[str, str]) -> Dict[str, str]:
metadata["title"] = record.get("title")
metadata["source"] = record.get("source")
metadata["url"] = record.get("url")
metadata["filename"] = record.get("filename")
return metadata
I put this function to use by instantiating the object and passing it as the metadata_func parameter,
loader = JSONLoader(
file_path,
jq_schema=jq_schema,
text_content=False,
content_key="text",
metadata_func=metadata_func
)
However, I would only be able to use the loader object on local json document with a path (file_path) on my file system.
In order to use this function to load json from a GCP bucket I need to create a function that takes in a file and its path (file_path) as well as the function to process the metadata about the speech's name, where it came from and return an instantiated JSONLoader object to read the file:
def load_json(file_path: str, jq_schema: str="."):
return JSONLoader(
file_path,
jq_schema=jq_schema,
text_content=False,
content_key="text",
metadata_func=metadata_func
)
Now I can pass this function to the LangChain's GCFSFileLoader. I can then instantiate the class to load file the first debate between Kennedy and Nixon from my GCP bucket. The full path for this json document is,
gs://kennedyskis/1st-nixon-kennedy-debate-19600926.jsonThe code to load the json document is,
loader = GCSFileLoader(project_name=credentials.project_id,
bucket="kennedyskis",
blob="1st-nixon-kennedy-debate-19600926.json",
loader_func=load_json)
document = loader.load()
This will return a list of LangChain Document(s). The text of the debate can be seen using the .page_content attribute,
print(document[0].page_content[:1000])
[Text, format, and style are as published in Freedom of Communications: Final Report of the Committee on Commerce, United States Senate..., Part III: The Joint Appearances of Senator John F. Kennedy and Vice President Richard M. Nixon and Other 1960 Campaign Presentations. 87th Congress, 1st Session, Senate Report No. 994, Part 3. Washington: U.S. Government Printing Office, 1961.] Monday, September 26, 1960 Originating CBS, Chicago, Ill., All Networks carried. Moderator, Howard K. Smith. MR. SMITH: Good evening. The television and radio stations of the United States and their affiliated stations are proud to provide facilities for a discussion of issues in the current political campaign by the two major candidates for the presidency. The candidates need no introduction. The Republican candidate, Vice President Richard M. Nixon, and the Democratic candidate, Senator John F. Kennedy. According to rules set by the candidates themselves, each man shall make an opening statement of approx
The metadata for the document can be seen from the .metadata attribute,
document[0].metadata
{'source': 'gs://kennedyskis/1st-nixon-kennedy-debate-19600926.json',
'seq_num': 1,
'title': 'Senator John F. Kennedy and Vice President Richard M. Nixon First Joint Radio-Television Broadcast, September 26, 1960',
'url': 'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/1st-nixon-kennedy-debate-19600926',
'filename': '1st-nixon-kennedy-debate-19600926'}
This debate document (and documents in generally) usually are too long to fit in the context window of an LLM so we need to break them up into smaller pieces of texts. This process is called "chunking". Below I will show how to break up the Nixon-Kennedy debate into "chunks" of 200 characters with 20 characters that overlap between chunks. I do this using the RecursiveCharacterTextSplitter class as shown below,
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=20)
documents = text_splitter.split_documents(document)
print("Number of documents: ", len(documents))
Number of documents: 429
Now we can look at the documents and their associated metadata,
for n, doc in enumerate(documents[:3]):
print(f"Doc {n}: ", doc.page_content, "\n", "\tMetadata:", doc.metadata, "\n")
Doc 0: [Text, format, and style are as published in Freedom of Communications: Final Report of the Committee on Commerce, United States Senate..., Part III: The Joint Appearances of Senator John F. Kennedy
Metadata: {'source': 'gs://kennedyskis/1st-nixon-kennedy-debate-19600926.json', 'seq_num': 1, 'title': 'Senator John F. Kennedy and Vice President Richard M. Nixon First Joint Radio-Television Broadcast, September 26, 1960', 'url': 'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/1st-nixon-kennedy-debate-19600926', 'filename': '1st-nixon-kennedy-debate-19600926'}
Doc 1: John F. Kennedy and Vice President Richard M. Nixon and Other 1960 Campaign Presentations. 87th Congress, 1st Session, Senate Report No. 994, Part 3. Washington: U.S. Government Printing Office,
Metadata: {'source': 'gs://kennedyskis/1st-nixon-kennedy-debate-19600926.json', 'seq_num': 1, 'title': 'Senator John F. Kennedy and Vice President Richard M. Nixon First Joint Radio-Television Broadcast, September 26, 1960', 'url': 'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/1st-nixon-kennedy-debate-19600926', 'filename': '1st-nixon-kennedy-debate-19600926'}
Doc 2: Printing Office, 1961.]
Metadata: {'source': 'gs://kennedyskis/1st-nixon-kennedy-debate-19600926.json', 'seq_num': 1, 'title': 'Senator John F. Kennedy and Vice President Richard M. Nixon First Joint Radio-Television Broadcast, September 26, 1960', 'url': 'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/1st-nixon-kennedy-debate-19600926', 'filename': '1st-nixon-kennedy-debate-19600926'}
Notice the metadata is the same for each of the documents since they all come from the same original json file.
Now that we have data that is loaded, well go over how to use embeddings to convert the text into vectors. I have covered embeddings in prior posts, so I won't go over it in much detail here. Instead I will focus on the LangChain commands needed to use embeddings. We can instantiate the LangChain NVIDIAEmbeddings class, which uses Nvidia's Llama 3.2 embeddings, and then use the embed_query method to embed a single document as shown:
embedding = embedding = NVIDIAEmbeddings(
model="nvidia/llama-3.2-nv-embedqa-1b-v2",
api_key=os.getenv("NVIDIA_API_KEY"),
dimension=2048,
truncate="NONE")
query = embedding.embed_query(documents[0].page_content)
Now we can see the first 5 entries of the vector,
print("First 5 entries in embedded document:", query[:5])
First 5 entries in embedded document: [-0.00730133056640625, 0.01448822021484375, 0.01450347900390625, 0.00974273681640625, 0.0265350341796875]
As well as the size of the vector:
print("Vector size:", len(query))
Vector size: 2048
The embedding of text is important for the retrivial process of RAG. We embed all our documents and then embed our question and use the embeddings help to perform semantic search which will improve the results of our search. I''ll touch on this a little more towards the end of this blog post.
4. Ingesting Speeches Into A Pinecone Vector Database ¶
Now we can load all of President Kennedys speeches using a GCSDirectoryLoader which loads an entire directoy in a bucket instead of just a single file. I can see the speeches of his presidency by getting the bucket and loading all the names of the speeches:
client = storage.Client(project=credentials.project_id,
credentials=credentials)
bucket = client.get_bucket("prezkennedyspeches")
speeches = [blob.name for blob in bucket.list_blobs()]
print(f"JFK had {len(speeches)} speeches in his presidency.")
JFK had 22 speeches in his presidency.
The speeches are:
speeches
['american-newspaper-publishers-association-19610427.json', 'american-society-of-newspaper-editors-19610420.json', 'american-university-19630610.json', 'americas-cup-dinner-19620914.json', 'berlin-crisis-19610725.json', 'berlin-w-germany-rudolph-wilde-platz-19630626.json', 'civil-rights-radio-and-television-report-19630611.json', 'cuba-radio-and-television-report-19621022.json', 'inaugural-address-19610120.json', 'inaugural-anniversary-19620120.json', 'irish-parliament-19630628.json', 'latin-american-diplomats-washington-dc-19610313.json', 'massachusetts-general-court-19610109.json', 'peace-corps-establishment-19610301.json', 'philadelphia-pa-19620704.json', 'rice-university-19620912.json', 'united-nations-19610925.json', 'united-states-congress-special-message-19610525.json', 'university-of-california-berkeley-19620323.json', 'university-of-mississippi-19620930.json', 'vanderbilt-university-19630518.json', 'yale-university-19620611.json']
Next I load all of the speeches using the GCSDirectoryLoader and split them into chunks of size 2,000 characters with 100 characters overlapping using theload_and_split method:
loader = GCSDirectoryLoader(
project_name=credentials.project_id,
bucket="prezkennedyspeches",
loader_func=load_json
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=100)
documents = loader.load_and_split(text_splitter)
print(f"There are {len(documents)} documents")
There are 180 documents
Now we're ready to connect to Pinecone and ingest the data into the vector database. I can create the connection to Pinecone using the command,
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
I'll create an index in Pinecone to store the documents. An index is basically a collection of embedded documents, similar to a table in a traditional database. Vector databases are specialized databases that allow for storage of vectors as well as for fast searches and retrivials. The vectors have numerical values and represents the documents in embedded form. The vectors are usually high dimensional (in our case 1,536 dimensions) and dense. However, compared to other representations of text such as the Bag-Of-Words model embedding vectors are relatively low dimensional. There are many benefits of vector embeddings and one of the most important is the ability to measure semantic similarity between two vectors. This allows us to measures the degree of similarity between pieces of text based on their meaning, rather than just the words used like would be the case with the Bag-Of-Words model. This property of embeddings is depicted below in the classic example,
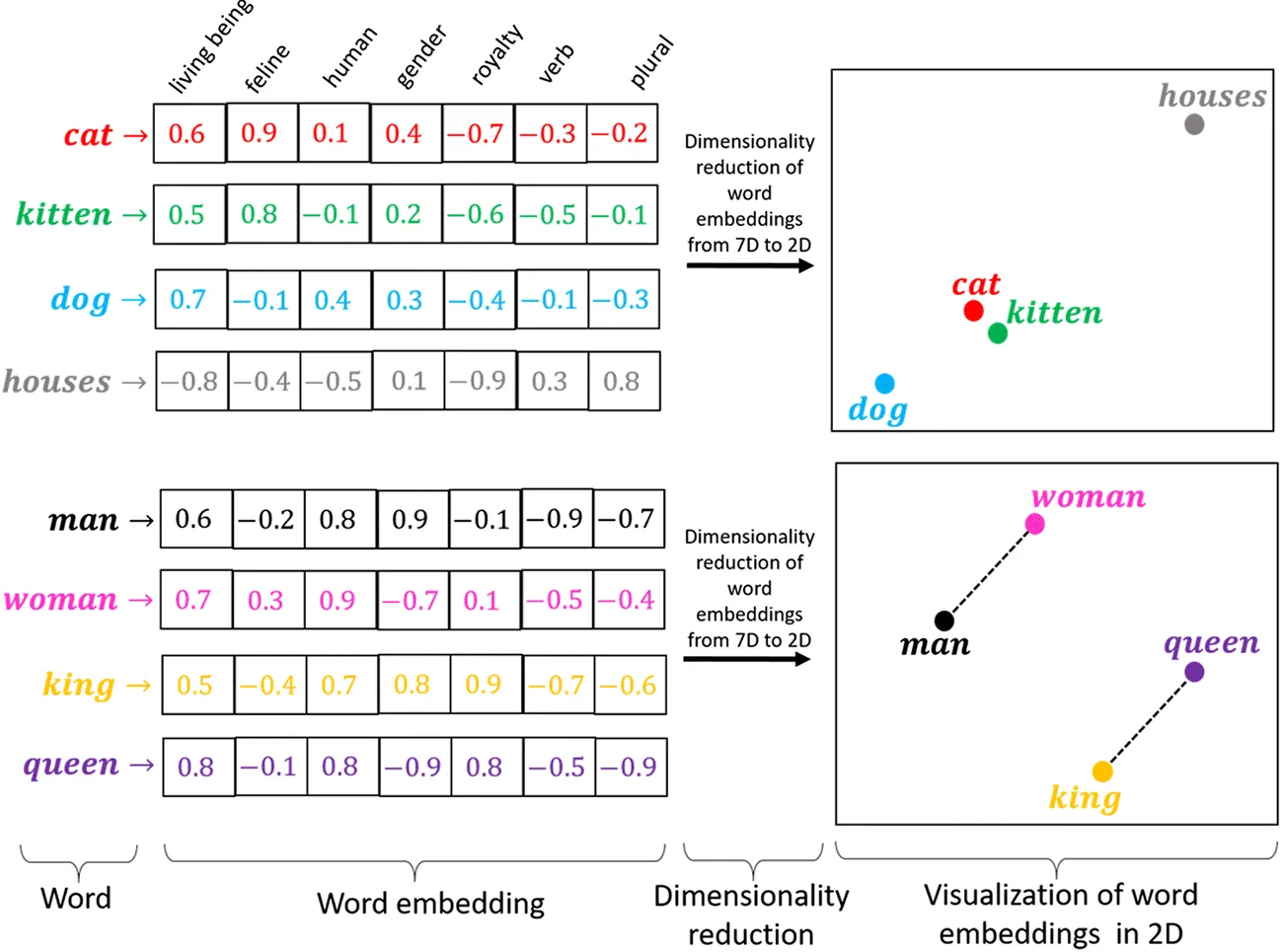
Words that have similar "meaning" and or are used in the same context like "cat" and "kitten" are closer together when represented as vectors in the embedding space then they are to the word "house". Embeddings allows to allow capture intrinsic relationships between words, such as the fact that "man" is to "king" as "woman" is to "queen".
The ability to capture and measure the closeness of words and text using embeddings allows us to perform semantic search. Semantic search will be extremely important for RAG models and will be discussed more in the next post. For now I'll give the index a name and declare the dimension of the vectors it will hold.
index_name = "prez-speeches"
dim = 2048
First I delete the index if it exists to clear it of all prior records.
# delete the index if it exists
if pc.has_index(index_name):
pc.delete_index(index_name)
Now I'll create the index that contains vectors of size dim:
# create the index
pc.create_index(
name=index_name,
dimension=dim,
metric="cosine",
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
{
"name": "prez-speeches",
"metric": "cosine",
"host": "prez-speeches-2307pwa.svc.aped-4627-b74a.pinecone.io",
"spec": {
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
},
"status": {
"ready": true,
"state": "Ready"
},
"vector_type": "dense",
"dimension": 2048,
"deletion_protection": "disabled",
"tags": null
}
Notice we have to declare a metric that is useful for the search. We can then get the statistics on the index we created,
print(pc.Index(index_name).describe_index_stats())
/Users/mikeharmon/miniconda3/envs/llm_env/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm
{'dimension': 2048,
'index_fullness': 0.0,
'metric': 'cosine',
'namespaces': {},
'total_vector_count': 0,
'vector_type': 'dense'}
It shows us that we can hold vectors of size 2,048 dimensions and that we have a total of 0 vectors currently in the index.
To ingest documents into the database as vectors we instantiate the PineconeVectorStore object, connect it to the index and pass the embedding object,
vectordb = PineconeVectorStore(
pinecone_api_key=os.getenv("PINECONE_API_KEY"),
embedding=embedding,
index_name=index_name
)
Now I'll load the documents into the index:
vectordb = vectordb.from_documents(
documents=documents,
embedding=embedding,
index_name=index_name
)
Under the hood LangChain will call the embedding.embed_documents method to convert the documents from text to numerical vectors and then ingest them into the database.
One of the beautiful things about LangChain is how the consistency of the API allows for easily swapping out and replacing different components of LLM applications. For instance one can switch to using a Chroma database and the syntax remains exactly the same! This characterstic of LangChain is important as each of the underlying databases and embedding models has their own API methods that are not necssarily consistent. Howevever, using LangChain we do have a consistent API and do not need to learn the different syntax for the different backends.
Now let's get the stats on the index again,
print(pc.Index(index_name).describe_index_stats())
{'dimension': 2048,
'index_fullness': 0.0,
'metric': 'cosine',
'namespaces': {'': {'vector_count': 180}},
'total_vector_count': 180,
'vector_type': 'dense'}
We can see that there are vectors ingested!
Now I can get the Pinecone API directl to get the index to use it to perform semantic search,
index = pc.Index(index_name)
This allows us to perform search for the semanticly closest documents to the queries. For instance I'll use the query,
question = "How did Kennedy feel about the Berlin Wall?"
Before I can perform search on the vector database I need to embed this text into a numerical vector,
query = embedding.embed_query(question)
Now I can find the 5 closest vectors to the query in the database,
matches = index.query(vector=query, top_k=5)
matches
{'matches': [{'id': 'b9e573a6-d9f9-4306-a6e3-72ac769643dd',
'score': 0.436862975,
'values': []},
{'id': 'd0245e9a-b4f2-46e6-a6d0-07ee3afbad16',
'score': 0.422326,
'values': []},
{'id': 'a6bcd4fa-90a3-46b2-a48d-105115ccaed7',
'score': 0.394667208,
'values': []},
{'id': 'ffe2db4a-6983-4cde-a853-658080619575',
'score': 0.35799697,
'values': []},
{'id': 'b7c5ebca-1886-4670-9acd-55ce4e402c2c',
'score': 0.352600902,
'values': []}],
'namespace': '',
'usage': {'read_units': 5}}
The results contain the similarity score as well as the document id. I can get the most relevant document by getting the first id in the results:
id = matches["matches"][0].get('id')
Then I can get the document for that id with the fetch method of the index:
result = index.fetch([id])
result.vectors[id]["metadata"]
{'filename': 'berlin-w-germany-rudolph-wilde-platz-19630626',
'seq_num': 1.0,
'source': 'gs://prezkennedyspeches/berlin-w-germany-rudolph-wilde-platz-19630626.json',
'text': 'Freedom has many difficulties and democracy is not perfect, but we have never had to put a wall up to keep our people in, to prevent them from leaving us. I want to say, on behalf of my countrymen, who live many miles away on the other side of the Atlantic, who are far distant from you, that they take the greatest pride that they have been able to share with you, even from a distance, the story of the last 18 years. I know of no town, no city, that has been besieged for 18 years that still lives with the vitality and the force, and the hope and the determination of the city of West Berlin. While the wall is the most obvious and vivid demonstration of the failures of the Communist system, for all the world to see, we take no satisfaction in it, for it is, as your Mayor has said, an offense not only against history but an offense against humanity, separating families, dividing husbands and wives and brothers and sisters, and dividing a people who wish to be joined together.\nWhat is true of this city is true of Germany--real, lasting peace in Europe can never be assured as long as one German out of four is denied the elementary right of free men, and that is to make a free choice. In 18 years of peace and good faith, this generation of Germans has earned the right to be free, including the right to unite their families and their nation in lasting peace, with good will to all people. You live in a defended island of freedom, but your life is part of the main. So let me ask you as I close, to lift your eyes beyond the dangers of today, to the hopes of tomorrow, beyond the freedom merely of this city of Berlin, or your country of Germany, to the advance of freedom everywhere, beyond the wall to the day of peace with justice, beyond yourselves and ourselves to all mankind.',
'title': 'Remarks of President John F. Kennedy at the Rudolph Wilde Platz, Berlin, June 26, 1963',
'url': 'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/berlin-w-germany-rudolph-wilde-platz-19630626'}
I can repeat the same exercise using the LangChain PineconeVectorStore api:
results = vectordb.search(query=question, search_type="similarity")
results[0].metadata
{'filename': 'berlin-w-germany-rudolph-wilde-platz-19630626',
'seq_num': 1.0,
'source': 'gs://prezkennedyspeches/berlin-w-germany-rudolph-wilde-platz-19630626.json',
'title': 'Remarks of President John F. Kennedy at the Rudolph Wilde Platz, Berlin, June 26, 1963',
'url': 'https://www.jfklibrary.org//archives/other-resources/john-f-kennedy-speeches/berlin-w-germany-rudolph-wilde-platz-19630626'}
The results are the same which is to be expected!
5. Next Steps ¶
In this post I covered how to scape websites using the aysncio and write them to Google Cloud Storage. After that we covered how to use LangChain to load text from cloud storage, chunk and embedded it using Nvidia Embeddings. Then we coved how to store the embedded documents as vectors in a Pinecone vector database and perform semantic search. In the next blog post I will build off using semantic search with Pinecone to build and deploy a RAG application that can answer questions on President Kennedy's speeches. I actually rewrote the notebook as a script that uses Langchain's async frameworks to load all 800+ JFK speeches into the Pinecone database and it is here if you are interested.